"""Week 1: Core Tools and Data Access functions for geospatial AI."""
import sys
import importlib.metadata
import warnings
import os
from typing import Dict, List, Tuple, Optional, Union
from pathlib import Path
import time
import logging
# Core geospatial libraries
import rasterio
from rasterio.windows import from_bounds
from rasterio.warp import transform_bounds
import numpy as np
import pandas as pd
#Include matplotlib for plt use.
import matplotlib.pyplot as plt
from pystac_client import Client
import planetary_computer as pc
warnings.filterwarnings('ignore')
# Configure logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def configure_gdal_environment() -> dict:
"""
Configure GDAL/PROJ environment variables for HPC and local systems.
This function addresses common GDAL/PROJ configuration issues, particularly
on HPC systems where proj.db may not be found or version mismatches exist.
Returns
-------
dict
Dictionary with configuration status and detected paths
"""
config_status = {
'gdal_configured': False,
'proj_configured': False,
'gdal_data_path': None,
'proj_lib_path': None,
'warnings': []
}
try:
import osgeo
from osgeo import gdal, osr
# Enable GDAL exceptions for better error handling
gdal.UseExceptions()
# Try to find PROJ data directory
proj_lib_candidates = [
os.environ.get('PROJ_LIB'),
os.environ.get('PROJ_DATA'),
os.path.join(sys.prefix, 'share', 'proj'),
os.path.join(sys.prefix, 'Library', 'share', 'proj'), # Windows
'/usr/share/proj', # Linux system
os.path.expanduser('~/mambaforge/share/proj'),
os.path.expanduser('~/miniconda3/share/proj'),
os.path.expanduser('~/anaconda3/share/proj'),
]
# Find valid PROJ directory
proj_lib_path = None
for candidate in proj_lib_candidates:
if candidate and os.path.isdir(candidate):
proj_db = os.path.join(candidate, 'proj.db')
if os.path.isfile(proj_db):
proj_lib_path = candidate
break
if proj_lib_path:
os.environ['PROJ_LIB'] = proj_lib_path
os.environ['PROJ_DATA'] = proj_lib_path
config_status['proj_lib_path'] = proj_lib_path
config_status['proj_configured'] = True
logger.info(f"PROJ configured: {proj_lib_path}")
else:
config_status['warnings'].append(
"Could not locate proj.db - coordinate transformations may fail")
# Try to find GDAL data directory
gdal_data_candidates = [
os.environ.get('GDAL_DATA'),
gdal.GetConfigOption('GDAL_DATA'),
os.path.join(sys.prefix, 'share', 'gdal'),
os.path.join(sys.prefix, 'Library', 'share', 'gdal'), # Windows
'/usr/share/gdal', # Linux system
]
gdal_data_path = None
for candidate in gdal_data_candidates:
if candidate and os.path.isdir(candidate):
gdal_data_path = candidate
break
if gdal_data_path:
os.environ['GDAL_DATA'] = gdal_data_path
gdal.SetConfigOption('GDAL_DATA', gdal_data_path)
config_status['gdal_data_path'] = gdal_data_path
config_status['gdal_configured'] = True
logger.info(f"GDAL_DATA configured: {gdal_data_path}")
# Additional GDAL configuration for network access
gdal.SetConfigOption('GDAL_DISABLE_READDIR_ON_OPEN', 'EMPTY_DIR')
gdal.SetConfigOption(
'CPL_VSIL_CURL_ALLOWED_EXTENSIONS', '.tif,.tiff,.vrt')
gdal.SetConfigOption('GDAL_HTTP_TIMEOUT', '300')
gdal.SetConfigOption('GDAL_HTTP_MAX_RETRY', '5')
# Test PROJ functionality
try:
srs = osr.SpatialReference()
srs.ImportFromEPSG(4326)
config_status['proj_test_passed'] = True
except Exception as e:
config_status['warnings'].append(f"PROJ test failed: {str(e)}")
config_status['proj_test_passed'] = False
return config_status
except Exception as e:
logger.error(f"Error configuring GDAL environment: {e}")
config_status['warnings'].append(f"Configuration error: {str(e)}")
return config_status
def verify_environment(required_packages: list) -> dict:
"""
Verify that all required packages are installed.
Parameters
----------
required_packages : list
List of package names to verify
Returns
-------
dict
Dictionary with package names as keys and versions as values
"""
results = {}
missing_packages = []
for package in required_packages:
try:
version = importlib.metadata.version(package)
results[package] = version
except importlib.metadata.PackageNotFoundError:
missing_packages.append(package)
results[package] = None
# Report results
if missing_packages:
logger.error(f"Missing packages: {', '.join(missing_packages)}")
return results
logger.info(f"All {len(required_packages)} packages verified")
return results1. Introduction
Welcome to your first hands-on session with geospatial AI! Today we’ll set up the core tools you’ll use throughout this course and get you working with real satellite imagery immediately. No theory-heavy introductions – we’re diving straight into practical data access and exploration.
Learning Goals
By the end of this session, you will:
- Have a working geospatial AI environment
- Pull real Sentinel-2/Landsat imagery via STAC APIs
- Load and explore satellite data with rasterio and xarray
- Create interactive maps with folium
- Understand the basics of multi-spectral satellite imagery
2. Environment Setup and Helper Functions
We’ll start by setting up our environment and creating reusable helper functions that you’ll use throughout the course. These functions handle common tasks like data loading, visualization, and processing.
2.1 Verify Your Environment
Environment Verification:
Before we begin, let’s verify that your environment is properly configured. Your environment should include the following packages:
- rasterio, xarray, rioxarray: Core geospatial data handling
- torch, transformers: Deep learning and foundation models
- folium: Interactive mapping
- matplotlib, numpy, pandas: Data analysis and visualization
- pystac-client, planetary-computer: STAC API access
- geopandas: Vector geospatial data
Verify that we have all the packages we need in our environment
# Verify core geospatial AI environment
required_packages = [
'rasterio', 'xarray', 'torch', 'transformers',
'folium', 'matplotlib', 'numpy', 'pandas',
'pystac-client', 'geopandas', 'rioxarray', 'planetary-computer'
]
package_status = verify_environment(required_packages)2025-10-09 12:58:26,691 - INFO - All 12 packages verifiedConfigure GDAL/PROJ Environment (Critical for HPC Systems)
Before we proceed with geospatial operations, we need to ensure GDAL and PROJ are properly configured. This is especially important on HPC systems where environment variables may not be automatically set.
# Configure GDAL/PROJ environment
gdal_config = configure_gdal_environment()
# Report configuration status
if gdal_config['proj_configured'] and gdal_config['gdal_configured']:
logger.info("GDAL/PROJ fully configured and ready")
elif gdal_config['proj_configured'] or gdal_config['gdal_configured']:
logger.warning("Partial GDAL/PROJ configuration - some operations may fail")
for warning in gdal_config['warnings']:
logger.warning(warning)
else:
logger.error("GDAL/PROJ configuration incomplete")
logger.error("This may cause issues with coordinate transformations")
for warning in gdal_config['warnings']:
logger.error(warning)2025-10-09 12:58:26,741 - INFO - PROJ configured: /Users/kellycaylor/mambaforge/envs/geoai/share/proj
2025-10-09 12:58:26,741 - INFO - GDAL_DATA configured: /Users/kellycaylor/mambaforge/envs/geoai/share/gdal
2025-10-09 12:58:26,753 - INFO - GDAL/PROJ fully configured and ready
Troubleshooting GDAL/PROJ Issues on HPC Systems
If you encounter GDAL/PROJ warnings or errors (especially “proj.db not found” or version mismatch warnings), try these solutions in order:
1. Manual Environment Variable Setup (Recommended for HPC)
Before running your Python script, set these environment variables in your shell:
# Find your conda environment path
conda info --envs
# Set PROJ_LIB and GDAL_DATA (adjust path to your environment)
export PROJ_LIB=$CONDA_PREFIX/share/proj
export PROJ_DATA=$CONDA_PREFIX/share/proj
export GDAL_DATA=$CONDA_PREFIX/share/gdal
# Verify the files exist
ls $PROJ_LIB/proj.db
ls $GDAL_DATA/2. Add to Your Job Script (SLURM/PBS)
For HPC batch jobs, add these lines to your job script:
#!/bin/bash
#SBATCH --job-name=geoai
#SBATCH --time=01:00:00
# Activate your conda environment
conda activate geoAI
# Set GDAL/PROJ paths
export PROJ_LIB=$CONDA_PREFIX/share/proj
export PROJ_DATA=$CONDA_PREFIX/share/proj
export GDAL_DATA=$CONDA_PREFIX/share/gdal
# Run your Python script
python your_script.py3. Permanently Set in Your Environment
Add to your ~/.bashrc or ~/.bash_profile:
# GDAL/PROJ configuration for geoAI environment
if [[ $CONDA_DEFAULT_ENV == "geoAI" ]]; then
export PROJ_LIB=$CONDA_PREFIX/share/proj
export PROJ_DATA=$CONDA_PREFIX/share/proj
export GDAL_DATA=$CONDA_PREFIX/share/gdal
fi4. Verify PROJ Installation
If problems persist, check your PROJ installation:
import pyproj
print(f"PROJ version: {pyproj.proj_version_str}")
print(f"PROJ data dir: {pyproj.datadir.get_data_dir()}")
# Check if proj.db exists
import os
proj_dir = pyproj.datadir.get_data_dir()
proj_db = os.path.join(proj_dir, 'proj.db')
print(f"proj.db exists: {os.path.exists(proj_db)}")5. Reinstall GDAL/PROJ (Last Resort)
If all else fails, reinstall with compatible versions:
conda activate geoAI
conda install -c conda-forge gdal=3.10 pyproj=3.7 rasterio=1.4 --force-reinstallCommon Error Messages and Solutions:
- “proj.db not found”: Set
PROJ_LIBenvironment variable - “DATABASE.LAYOUT.VERSION mismatch”: Multiple PROJ installations; ensure you’re using the one from your conda environment
- “CPLE_AppDefined in PROJ”: GDAL is finding wrong PROJ installation; set environment variables explicitly
- Slow performance: Network timeout issues; the
configure_gdal_environment()function sets appropriate timeouts
2.2 Import Essential Libraries and Create Helper Functions
Before diving into geospatial data analysis and AI workflows, it’s important to import the essential Python libraries that form the backbone of this toolkit. The following code block brings together core geospatial libraries such as rasterio for raster data handling, xarray and rioxarray for multi-dimensional array operations, geopandas for vector data, and pystac-client for accessing spatiotemporal asset catalogs.
Visualization is supported by matplotlib and folium, while torch enables deep learning workflows. Additional utilities for data handling, logging, and reproducibility are also included. These libraries collectively provide a robust foundation for geospatial AI projects.
# Core geospatial libraries
import rasterio
from rasterio.warp import calculate_default_transform, reproject, Resampling
import xarray as xr
import rioxarray # Extends xarray with rasterio functionality
# Data access and processing
import numpy as np
import pandas as pd
import geopandas as gpd
from pystac_client import Client
import planetary_computer as pc # For signing asset URLs
# Visualization
import matplotlib.pyplot as plt
import folium
from folium import plugins
# Utilities
from typing import Dict, List, Tuple, Optional, Union
from pathlib import Path
import json
import time
from datetime import datetime, timedelta
import logging
# Deep learning libraries
import torchSet up some standard plot configuration options.
# Configure matplotlib for publication-quality plots
plt.rcParams.update({
'figure.figsize': (10, 6),
'figure.dpi': 100,
'font.size': 10,
'axes.titlesize': 12,
'axes.labelsize': 10,
'xtick.labelsize': 9,
'ytick.labelsize': 9,
'legend.fontsize': 9
})2.3 Setup Logging for our workflow
Logging is a crucial practice in data science and geospatial workflows, enabling you to track code execution, monitor data processing steps, and quickly diagnose issues. By setting up logging, you ensure that your analyses are reproducible and errors are easier to trace—especially important in production or collaborative environments. For more on logging in data science, see Effective Logging for Data Science and the Python logging HOWTO.
# Configure logging for production-ready code
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)2.4 Geospatial AI Toolkit: Comprehensive Helper Functions
This chapter is organized to guide you through the essential foundations of geospatial data science and AI. The file is structured into clear sections, each focusing on a key aspect of the geospatial workflow:
- Library Imports and Setup: All necessary Python packages are imported and configured for geospatial analysis and visualization.
- Helper Functions: Modular utility functions are introduced to streamline common geospatial tasks.
- Sectioned Capabilities: Each major capability (such as authentication, data access, and processing) is presented in its own section, with explanations of the underlying design patterns and best practices.
- Progressive Complexity: Concepts and code build on each other, moving from foundational tools to more advanced techniques.
This structure is designed to help you understand not just how to use the tools, but also why certain architectural and security decisions are made—preparing you for both practical work and deeper learning as you progress through the course.
2.4.1 STAC Authentication and Security 🔐
Learning Objectives
- Understand API authentication patterns for production systems
- Implement secure credential management for cloud services
- Design robust authentication with fallback mechanisms
- Apply enterprise security best practices to geospatial workflows
Why Authentication Matters in Geospatial AI
Modern satellite data access relies on cloud-native APIs that require proper authentication for:
- Rate Limit Management: Authenticated users get higher request quotas
- Access Control: Some datasets require institutional or commercial access
- Usage Tracking: Providers need to monitor and bill for data access
- Security: Prevents abuse and ensures sustainable data sharing
How to Obtain a Microsoft Planetary Computer API Key
To access premium datasets and higher request quotas on the Microsoft Planetary Computer, you need to obtain a free API key. Follow these steps:
- Sign in with a Microsoft Account
- Visit the Planetary Computer sign-in page.
- Click Sign in and log in using your Microsoft, GitHub, or LinkedIn account.
- Request an API Key
- After signing in, navigate to the API Keys section.
- Click Request API Key.
- Fill out the brief form describing your intended use (e.g., “For coursework in geospatial data science”).
- Submit the request. Approval is usually instant for academic and research use.
- Copy Your API Key
- Once approved, your API key will be displayed on the page.
- Copy the key and keep it secure. Do not share it publicly.
- Set the API Key for Your Code
Recommended (for local development):
Create a file named.envin your project directory and add the following line:PC_SDK_SUBSCRIPTION_KEY=your_api_key_hereAlternatively (for temporary use):
Set the environment variable in your terminal before running your code:export PC_SDK_SUBSCRIPTION_KEY=your_api_key_here
- Verify Authentication
- When you run the code in this chapter, it will automatically detect your API key and authenticate you with the Planetary Computer.
Tip: If you lose your API key, you can always return to the API Keys page to view or regenerate it.
def setup_planetary_computer_auth() -> bool:
"""
Configure authentication for Microsoft Planetary Computer.
Uses environment variables and .env files for credential discovery,
with graceful degradation to anonymous access.
Returns
-------
bool
True if authenticated, False for anonymous access
"""
# Try environment variables first (production)
auth_key = os.getenv('PC_SDK_SUBSCRIPTION_KEY') or os.getenv('PLANETARY_COMPUTER_API_KEY')
# Fallback to .env file (development)
if not auth_key:
env_file = Path('.env')
if env_file.exists():
try:
with open(env_file) as f:
for line in f:
line = line.strip()
if line.startswith(('PC_SDK_SUBSCRIPTION_KEY=', 'PLANETARY_COMPUTER_API_KEY=')):
auth_key = line.split('=', 1)[1].strip().strip('"\'')
break
except Exception:
pass # Continue with anonymous access
# Configure authentication
if auth_key and len(auth_key) > 10:
try:
pc.set_subscription_key(auth_key)
logger.info("Planetary Computer authentication successful")
return True
except Exception as e:
logger.warning(f"Authentication failed: {e}")
logger.info("Using anonymous access (basic rate limits)")
return FalseAuthenticate to the Planetary Computer
# Initialize authentication
auth_status = setup_planetary_computer_auth()
logger.info(f"Planetary Computer authentication status: {'Authenticated' if auth_status else 'Anonymous'}")2025-10-09 12:58:28,431 - INFO - Using anonymous access (basic rate limits)
2025-10-09 12:58:28,432 - INFO - Planetary Computer authentication status: Anonymous
Security Best Practices
- Never hardcode credentials in source code or notebooks
- Use environment variables for production deployments
2.4.2 STAC Data Discovery 🔍
Learning Objectives
- Master cloud-native data discovery patterns
- Understand STAC query optimization strategies
- Implement robust search with intelligent filtering
- Design scalable data discovery for large-scale analysis
Cloud-Native Data Access Architecture
STAC APIs represent a paradigm shift from traditional data distribution:
- Federated Catalogs: Multiple providers, unified interface
- On-Demand Access: No need to download entire datasets
- Rich Metadata: Searchable properties for precise discovery
- Cloud Optimization: Direct access to cloud-optimized formats
The code block below defines a function, search_sentinel2_scenes, which enables us to programmatically search for Sentinel-2 Level 2A satellite imagery using the Microsoft Planetary Computer (MPC) STAC API.
Here’s how it works:
- Inputs: You provide a bounding box (
bbox), a date range (date_range), a maximum allowed cloud cover (cloud_cover_max), and a limit on the number of results. - STAC Search: The function connects to the MPC’s STAC API endpoint and performs a search for Sentinel-2 scenes that match your criteria.
- Filtering: It filters results by cloud cover and sorts them so that the clearest images (lowest cloud cover) come first.
- Output: The function returns a list of STAC items (scenes) that you can further analyze or download.
def search_sentinel2_scenes(
bbox: List[float],
date_range: str,
cloud_cover_max: float = 20,
limit: int = 10
) -> List:
"""
Search Sentinel-2 Level 2A scenes using STAC API.
Parameters
----------
bbox : List[float]
Bounding box as [west, south, east, north] in WGS84
date_range : str
ISO date range: "YYYY-MM-DD/YYYY-MM-DD"
cloud_cover_max : float
Maximum cloud cover percentage
limit : int
Maximum scenes to return
Returns
-------
List[pystac.Item]
List of STAC items sorted by cloud cover (ascending)
"""
catalog = Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=pc.sign_inplace
)
search_params = {
"collections": ["sentinel-2-l2a"],
"bbox": bbox,
"datetime": date_range,
"query": {"eo:cloud_cover": {"lt": cloud_cover_max}},
"limit": limit
}
search_results = catalog.search(**search_params)
items = list(search_results.items())
# Sort by cloud cover (best quality first)
items.sort(key=lambda x: x.properties.get('eo:cloud_cover', 100))
logger.info(f"Found {len(items)} Sentinel-2 scenes (cloud cover < {cloud_cover_max}%)")
return itemsWhile the search_sentinel2_scenes function is currently tailored for Sentinel-2 imagery from the Microsoft Planetary Computer (MPC) STAC, it can be easily adapted to access other types of imagery or even different STAC endpoints.
To search for other datasets—such as Landsat, NAIP, or commercial imagery—you can modify the "collections" parameter in the search_params dictionary to reference the desired collection (e.g., "landsat-8-c2-l2" for Landsat 8). Additionally, to query a different STAC API (such as a local STAC server or another cloud provider), simply change the Client.open() URL to the appropriate endpoint. You may also adjust the search filters (e.g., properties like spatial resolution, acquisition mode, or custom metadata fields) to suit the requirements of other imagery types.
The search_STAC_scenes function generalizes our search_sentinel2_scenes by allowing keyword parameters that define the collection and the URL to use to access the STAC. This flexibility allows you to leverage the same search pattern for a wide variety of geospatial datasets across multiple STAC-compliant catalogs.
def search_STAC_scenes(
bbox: list,
date_range: str,
cloud_cover_max: float = 100.0,
limit: int = 10,
collection: str = "sentinel-2-l2a",
stac_url: str = "https://planetarycomputer.microsoft.com/api/stac/v1",
client_modifier=None,
extra_query: dict = None
) -> list:
"""
General-purpose function to search STAC scenes using a STAC API.
Parameters
----------
bbox : List[float]
Bounding box as [west, south, east, north] in WGS84
date_range : str
ISO date range: "YYYY-MM-DD/YYYY-MM-DD"
cloud_cover_max : float, optional
Maximum cloud cover percentage (default: 100.0)
limit : int, optional
Maximum scenes to return (default: 10)
collection : str, optional
STAC collection name (default: "sentinel-2-l2a")
stac_url : str, optional
STAC API endpoint URL (default: MPC STAC)
client_modifier : callable, optional
Optional function to modify the STAC client (e.g., for auth)
extra_query : dict, optional
Additional query parameters for the search
Returns
-------
List[pystac.Item]
List of STAC items sorted by cloud cover (ascending, if available).
Examples
--------
>>> # Search for Sentinel-2 scenes (default) on the Microsoft Planetary Computer (default)
>>> # over a bounding box in Oregon in January 2022
>>> bbox = [-123.5, 45.0, -122.5, 46.0]
>>> date_range = "2022-01-01/2022-01-31"
>>> items = search_STAC_scenes(bbox, date_range, cloud_cover_max=10, limit=5)
>>> # Search for Landsat 8 scenes from a different STAC endpoint
>>> landsat_url = "https://earth-search.aws.element84.com/v1"
>>> items = search_STAC_scenes(
... bbox,
... "2021-06-01/2021-06-30",
... collection="landsat-8-c2-l2",
... stac_url=landsat_url,
... cloud_cover_max=20,
... limit=3
... )
>>> # Add an extra query to filter by platform
>>> items = search_STAC_scenes(
... bbox,
... date_range,
... extra_query={"platform": {"eq": "sentinel-2b"}}
... )
"""
# Open the STAC client, with optional modifier (e.g., for MPC auth)
if client_modifier is not None:
catalog = Client.open(stac_url, modifier=client_modifier)
else:
catalog = Client.open(stac_url)
# Build query parameters
search_params = {
"collections": [collection],
"bbox": bbox,
"datetime": date_range,
"limit": limit
}
# Add cloud cover filter if present
if cloud_cover_max < 100.0:
search_params["query"] = {"eo:cloud_cover": {"lt": cloud_cover_max}}
if extra_query:
# Merge extra_query into search_params['query']
if "query" not in search_params:
search_params["query"] = {}
search_params["query"].update(extra_query)
search_results = catalog.search(**search_params)
items = list(search_results.items())
# Sort by cloud cover if available
items.sort(key=lambda x: x.properties.get('eo:cloud_cover', 100))
logger.info(
f"Found {len(items)} scenes in collection '{collection}' (cloud cover < {cloud_cover_max}%)"
)
return items
Query Optimization Strategies
- Spatial Indexing: STAC APIs use spatial indices for fast geographic queries
- Temporal Partitioning: Date-based organization enables efficient time series queries
- Property Filtering: Server-side filtering reduces network transfer
- Result Ranking: Sort by quality metrics (cloud cover, viewing angle) for best-first selection
2.4.3 Intelligent Data Loading 📥
Learning Objectives
- Implement memory-efficient satellite data loading
- Master coordinate reference system (CRS) transformations
- Design robust error handling for network operations
- Optimize data transfer with intelligent subsetting
Memory Management in Satellite Data Processing
Satellite scenes can be massive (>1GB per scene), requiring intelligent loading strategies. The next block of code demonstrates how to efficiently load satellite data by implementing several optimization strategies:
- Lazy Loading: Data is only read from disk or over the network when explicitly requested, rather than preloading entire scenes. This conserves memory and speeds up initial operations.
- Subset Loading: By allowing a
subset_bboxparameter, only the region of interest is loaded into memory, reducing both data transfer and RAM usage. - Retry Logic: Network interruptions are handled gracefully with automatic retries, improving robustness for large or remote datasets.
- Progressive Loading: The function is designed to handle multi-band and multi-resolution data, enabling users to load only the bands they need.
Together, these techniques ensure that satellite data processing is both memory- and network-efficient, making it practical to work with large geospatial datasets on typical hardware.
def load_sentinel2_bands(
item,
bands: List[str] = ['B04', 'B03', 'B02', 'B08'],
subset_bbox: Optional[List[float]] = None,
max_retries: int = 3
) -> Dict[str, Union[np.ndarray, str]]:
"""
Load Sentinel-2 bands with optional spatial subsetting.
Parameters
----------
item : pystac.Item
STAC item representing the satellite scene
bands : List[str]
Spectral bands to load
subset_bbox : Optional[List[float]]
Spatial subset as [west, south, east, north] in WGS84
max_retries : int
Number of retry attempts per band
Returns
-------
Dict[str, Union[np.ndarray, str]]
Band arrays plus georeferencing metadata
"""
from rasterio.windows import from_bounds
from rasterio.warp import transform_bounds
band_data = {}
successful_bands = []
failed_bands = []
for band_name in bands:
if band_name not in item.assets:
failed_bands.append(band_name)
continue
asset_url = item.assets[band_name].href
# Retry logic with exponential backoff
for attempt in range(max_retries):
try:
# URL signing for authenticated access
signed_url = pc.sign(asset_url)
# Memory-efficient loading with rasterio
with rasterio.open(signed_url) as src:
# Validate data source
if src.width == 0 or src.height == 0:
raise ValueError(f"Invalid raster dimensions: {src.width}x{src.height}")
if subset_bbox:
# Intelligent subsetting with CRS transformation
try:
# Transform bbox to source CRS if needed
if src.crs != rasterio.crs.CRS.from_epsg(4326):
subset_bbox_src_crs = transform_bounds(
rasterio.crs.CRS.from_epsg(4326), src.crs, *subset_bbox
)
else:
subset_bbox_src_crs = subset_bbox
# Calculate reading window
window = from_bounds(*subset_bbox_src_crs, src.transform)
# Ensure window is within raster bounds
window = window.intersection(
rasterio.windows.Window(0, 0, src.width, src.height)
)
if window.width > 0 and window.height > 0:
data = src.read(1, window=window)
transform = src.window_transform(window)
bounds = rasterio.windows.bounds(window, src.transform)
if src.crs != rasterio.crs.CRS.from_epsg(4326):
bounds = transform_bounds(src.crs, rasterio.crs.CRS.from_epsg(4326), *bounds)
else:
# Fall back to full scene
data = src.read(1)
transform = src.transform
bounds = src.bounds
except Exception:
# Fall back to full scene on subset error
data = src.read(1)
transform = src.transform
bounds = src.bounds
else:
# Load full scene
data = src.read(1)
transform = src.transform
bounds = src.bounds
if data.size == 0:
raise ValueError("Loaded data has zero size")
# Store band data and metadata
band_data[band_name] = data
if 'transform' not in band_data:
band_data.update({
'transform': transform,
'crs': src.crs,
'bounds': bounds,
'scene_id': item.id,
'date': item.properties['datetime'].split('T')[0]
})
successful_bands.append(band_name)
break
except Exception as e:
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # Exponential backoff
continue
else:
failed_bands.append(band_name)
logger.warning(f"Failed to load band {band_name}: {str(e)[:50]}")
break
# Validate results
if len(successful_bands) == 0:
raise Exception(f"Failed to load any bands from scene {item.id}")
if failed_bands:
logger.warning(f"Failed to load {len(failed_bands)} bands: {failed_bands}")
logger.info(f"Successfully loaded {len(successful_bands)} bands: {successful_bands}")
return band_data
Memory Management Best Practices
- Use windowed reading for large rasters to control memory usage
- Load bands on-demand rather than all at once
- Implement progress monitoring for user feedback during long operations
- Handle CRS transformations automatically to ensure spatial consistency
- Cache georeferencing metadata to avoid redundant I/O operations
2.4.4 Scene Processing and Subsetting 📐
Learning Objectives
- Master percentage-based spatial subsetting for reproducible analysis
- Understand scene geometry and coordinate system implications
- Design scalable spatial partitioning strategies
- Implement adaptive processing based on scene characteristics
Spatial Reasoning in Satellite Data Analysis
Satellite scenes come in various sizes and projections, requiring intelligent spatial handling:
- Percentage-Based Subsetting: Resolution-independent spatial cropping
- Adaptive Processing: Adjust strategies based on scene characteristics
- Spatial Metadata: Consistent georeferencing across operations
- Tiling Strategies: Partition large scenes for parallel processing
What does the next block of code do, and why is it useful for GeoAI workflows?
The next block of code defines a function for percentage-based spatial subsetting of satellite scenes. Instead of specifying exact coordinates or pixel indices, you provide percentage ranges (e.g., 25% to 75%) for both the x (longitude) and y (latitude) axes. The function then calculates the corresponding bounding box in geographic coordinates.
How does this help in GeoAI workflows? - Resolution Independence: The same percentage-based subset works for any scene, regardless of its pixel size or spatial resolution. - Reproducibility: Analyses can be repeated on different scenes or at different times, always extracting the same relative region. - Scalability: Enables systematic tiling or grid-based sampling for large-scale or distributed processing. - Adaptability: Easily adjust the subset size or location based on scene characteristics or model requirements. - Abstraction: Hides the complexity of coordinate systems and scene geometry, making spatial operations more accessible and less error-prone.
This approach is especially valuable in GeoAI, where consistent, automated, and scalable spatial sampling is critical for training, validating, and deploying machine learning models on geospatial data.
def get_subset_from_scene(
item,
x_range: Tuple[float, float] = (25, 75),
y_range: Tuple[float, float] = (25, 75),
) -> List[float]:
"""
Intelligent spatial subsetting using percentage-based coordinates.
This approach provides several advantages:
1. Resolution Independence: Works regardless of scene size or pixel resolution
2. Reproducibility: Same percentage always gives same relative location
3. Scalability: Easy to create systematic grids for batch processing
4. Adaptability: Can adjust subset size based on scene characteristics
Parameters
----------
item : pystac.Item
STAC item containing scene geometry
x_range : Tuple[float, float]
Longitude percentage range (0-100)
y_range : Tuple[float, float]
Latitude percentage range (0-100)
Returns
-------
List[float]
Subset bounding box [west, south, east, north] in WGS84
Design Pattern: Template Method with Spatial Reasoning
- Provides consistent interface for varied spatial operations
- Encapsulates coordinate system complexity
- Enables systematic spatial sampling strategies
"""
# Extract scene geometry from STAC metadata
scene_bbox = item.bbox # [west, south, east, north]
# Input validation for percentage ranges
if not (0 <= x_range[0] < x_range[1] <= 100):
raise ValueError(
f"Invalid x_range: {x_range}. Must be (min, max) with 0 <= min < max <= 100"
)
if not (0 <= y_range[0] < y_range[1] <= 100):
raise ValueError(
f"Invalid y_range: {y_range}. Must be (min, max) with 0 <= min < max <= 100"
)
# Calculate scene dimensions in geographic coordinates
scene_width = scene_bbox[2] - scene_bbox[0] # east - west
scene_height = scene_bbox[3] - scene_bbox[1] # north - south
# Convert percentages to geographic coordinates
west = scene_bbox[0] + (x_range[0] / 100.0) * scene_width
east = scene_bbox[0] + (x_range[1] / 100.0) * scene_width
south = scene_bbox[1] + (y_range[0] / 100.0) * scene_height
north = scene_bbox[1] + (y_range[1] / 100.0) * scene_height
subset_bbox = [west, south, east, north]
return subset_bboxdef get_scene_info(item):
"""
Extract comprehensive scene characteristics for adaptive processing.
Parameters
----------
item : pystac.Item
STAC item to analyze
Returns
-------
Dict
Scene characteristics including dimensions and geographic metrics
Design Pattern: Information Expert
- Centralizes scene analysis logic
- Provides basis for adaptive processing decisions
- Enables consistent scene characterization across workflows
"""
bbox = item.bbox
width_deg = bbox[2] - bbox[0]
height_deg = bbox[3] - bbox[1]
# Approximate conversion to kilometers (suitable for most latitudes)
center_lat = (bbox[1] + bbox[3]) / 2
width_km = width_deg * 111 * np.cos(np.radians(center_lat))
height_km = height_deg * 111
info = {
"scene_id": item.id,
"date": item.properties["datetime"].split("T")[0],
"bbox": bbox,
"width_deg": width_deg,
"height_deg": height_deg,
"width_km": width_km,
"height_km": height_km,
"area_km2": width_km * height_km,
"center_lat": center_lat,
"center_lon": (bbox[0] + bbox[2]) / 2,
}
return info
Spatial Processing Design Patterns
- Percentage-based coordinates provide resolution independence
- Adaptive processing adjusts strategies based on scene size
- Systematic spatial sampling enables reproducible analysis
- Geographic metrics support intelligent subset sizing decisions
2.4.5 Data Processing Pipelines 🔬
Learning Objectives
- Master spectral analysis and vegetation index calculations
- Implement robust statistical analysis with error handling
- Design composable processing functions for workflow flexibility
- Understand radiometric enhancement techniques for visualization
Spectral Analysis Fundamentals
Satellite sensors capture electromagnetic radiation across multiple spectral bands, enabling sophisticated analysis:
- Radiometric Enhancement: Optimize visual representation of spectral data
- Vegetation Indices: Combine bands to highlight biological activity
- Statistical Analysis: Characterize data distributions and quality
- Composable Functions: Build complex workflows from simple operations
Band Normalization
The normalize_band function performs percentile-based normalization of a satellite image band (a 2D NumPy array of pixel values). Its main purpose is to enhance the visual contrast of the data for display or further analysis, while being robust to outliers and invalid values.
How it works: - Input: The function takes a NumPy array (band) representing the raw values of a spectral band, a tuple of percentiles (defaulting to the 2nd and 98th), and a clip flag. - Robustness: It first creates a mask to identify valid (finite) values, ignoring NaNs and infinities. - Percentile Stretch: It computes the lower and upper percentile values (p_low, p_high) from the valid data. These percentiles define the range for stretching, which helps ignore extreme outliers. - Normalization: The band is linearly scaled so that p_low maps to 0 and p_high maps to 1. Values outside this range can be optionally clipped. - Edge Cases: If all values are invalid or the percentiles are equal (no variation), it returns an array of zeros.
Why use this? - It improves image contrast for visualization. - It is robust to outliers and missing data. - It preserves the relative relationships between pixel values.
This function exemplifies the “Strategy Pattern” by encapsulating a normalization approach that can be swapped or extended for other enhancement strategies.
def normalize_band(
band: np.ndarray, percentiles: Tuple[float, float] = (2, 98), clip: bool = True
) -> np.ndarray:
"""
Percentile-based radiometric enhancement for optimal visualization.
This normalization approach addresses several challenges:
1. Dynamic Range: Raw satellite data often has poor contrast
2. Outlier Robustness: Percentiles ignore extreme values
3. Visual Optimization: Results in pleasing, interpretable images
4. Statistical Validity: Preserves relative data relationships
Parameters
----------
band : np.ndarray
Raw satellite band values
percentiles : Tuple[float, float]
Lower and upper percentiles for stretching
clip : bool
Whether to clip values to [0, 1] range
Returns
-------
np.ndarray
Normalized band values optimized for visualization
Design Pattern: Strategy Pattern for Enhancement
- Encapsulates different enhancement algorithms
- Provides consistent interface for various normalization strategies
- Handles edge cases (NaN, infinite values) robustly
"""
# Handle NaN and infinite values robustly
valid_mask = np.isfinite(band)
if not np.any(valid_mask):
return np.zeros_like(band)
# Calculate percentiles on valid data only
p_low, p_high = np.percentile(band[valid_mask], percentiles)
# Avoid division by zero
if p_high == p_low:
return np.zeros_like(band)
# Linear stretch based on percentiles
normalized = (band - p_low) / (p_high - p_low)
# Optional clipping to [0, 1] range
if clip:
normalized = np.clip(normalized, 0, 1)
return normalizedRGB Composite
The next code block introduces the function create_rgb_composite, which is designed to generate publication-quality RGB composite images from individual spectral bands (red, green, and blue). This function optionally applies automatic contrast enhancement to each band using the previously defined normalize_band function, ensuring that the resulting composite is visually optimized and suitable for analysis or presentation. The function demonstrates the Composite design pattern by combining multiple bands into a unified RGB representation, applying consistent processing across all channels, and producing an output format compatible with standard visualization libraries.
def create_rgb_composite(
red: np.ndarray, green: np.ndarray, blue: np.ndarray, enhance: bool = True
) -> np.ndarray:
"""
Create publication-quality RGB composite images.
Parameters
----------
red, green, blue : np.ndarray
Individual spectral bands
enhance : bool
Apply automatic contrast enhancement
Returns
-------
np.ndarray
RGB composite with shape (height, width, 3)
Design Pattern: Composite Pattern for Multi-band Operations
- Combines multiple bands into unified representation
- Applies consistent enhancement across all channels
- Produces standard format for visualization libraries
"""
# Apply enhancement to each channel
if enhance:
red_norm = normalize_band(red)
green_norm = normalize_band(green)
blue_norm = normalize_band(blue)
else:
# Simple linear scaling
red_norm = red / np.max(red) if np.max(red) > 0 else red
green_norm = green / np.max(green) if np.max(green) > 0 else green
blue_norm = blue / np.max(blue) if np.max(blue) > 0 else blue
# Stack into RGB composite
rgb_composite = np.dstack([red_norm, green_norm, blue_norm])
return rgb_compositeDerived band calculations
The following code block introduces the function calculate_ndvi, which computes the Normalized Difference Vegetation Index (NDVI) from near-infrared (NIR) and red spectral bands. NDVI is a widely used vegetation index in remote sensing, defined as (NIR - Red) / (NIR + Red). This index leverages the fact that healthy vegetation strongly reflects NIR light while absorbing red light due to chlorophyll, making NDVI a robust indicator of plant health, biomass, and vegetation cover. The function includes robust error handling for numerical stability and edge cases, ensuring reliable results even when input values are near zero or contain invalid data.
def calculate_ndvi(
nir: np.ndarray, red: np.ndarray, epsilon: float = 1e-8
) -> np.ndarray:
"""
Calculate Normalized Difference Vegetation Index with robust error handling.
NDVI = (NIR - Red) / (NIR + Red)
NDVI is fundamental to vegetation monitoring because:
1. Physical Basis: Reflects chlorophyll absorption and cellular structure
2. Standardization: Normalized to [-1, 1] range for comparison
3. Temporal Stability: Enables change detection across seasons/years
4. Ecological Meaning: Strong correlation with biomass and health
Parameters
----------
nir : np.ndarray
Near-infrared reflectance (Band 8: 842nm)
red : np.ndarray
Red reflectance (Band 4: 665nm)
epsilon : float
Numerical stability constant
Returns
-------
np.ndarray
NDVI values in range [-1, 1]
Design Pattern: Domain-Specific Language for Spectral Indices
- Encapsulates spectral physics knowledge
- Provides numerical stability for edge cases
- Enables consistent index calculation across projects
"""
# Convert to float for numerical precision
nir_float = nir.astype(np.float32)
red_float = red.astype(np.float32)
# Calculate NDVI with numerical stability
numerator = nir_float - red_float
denominator = nir_float + red_float + epsilon
ndvi = numerator / denominator
# Handle edge cases (both bands zero, etc.)
ndvi = np.where(np.isfinite(ndvi), ndvi, 0)
return ndviBand statistics
The next function, calculate_band_statistics, provides a comprehensive statistical summary of a satellite image band. It computes key statistics such as minimum, maximum, mean, standard deviation, median, and percentiles, as well as counts of valid and total pixels. This function is essential in GeoAI workflows for several reasons:
- Data Quality Assessment: By summarizing the distribution and quality of pixel values, it helps identify anomalies, outliers, or missing data before further analysis.
- Feature Engineering: Statistical summaries can be used as features in machine learning models for land cover classification, anomaly detection, or change detection.
- Automated Validation: Integrating this function into data pipelines enables automated quality control, ensuring only reliable data is used for downstream tasks.
- Reporting and Visualization: The output can be used to generate reports or visualizations that communicate data characteristics to stakeholders.
In practice, calculate_band_statistics can be called on each band of a satellite image to quickly assess data readiness and inform preprocessing or modeling decisions in GeoAI projects.
def calculate_band_statistics(band: np.ndarray, name: str = "Band") -> Dict:
"""
Comprehensive statistical characterization of satellite bands.
Parameters
----------
band : np.ndarray
Input band array
name : str
Descriptive name for reporting
Returns
-------
Dict
Complete statistical summary including percentiles and counts
Design Pattern: Observer Pattern for Data Quality Assessment
- Provides standardized quality metrics
- Enables data validation and quality control
- Supports automated quality assessment workflows
"""
valid_mask = np.isfinite(band)
valid_data = band[valid_mask]
if len(valid_data) == 0:
return {
"name": name,
"min": np.nan,
"max": np.nan,
"mean": np.nan,
"std": np.nan,
"median": np.nan,
"valid_pixels": 0,
"total_pixels": band.size,
}
stats = {
"name": name,
"min": float(np.min(valid_data)),
"max": float(np.max(valid_data)),
"mean": float(np.mean(valid_data)),
"std": float(np.std(valid_data)),
"median": float(np.median(valid_data)),
"valid_pixels": int(np.sum(valid_mask)),
"total_pixels": int(band.size),
"percentiles": {
"p25": float(np.percentile(valid_data, 25)),
"p75": float(np.percentile(valid_data, 75)),
"p95": float(np.percentile(valid_data, 95)),
},
}
return stats
Spectral Analysis Best Practices
- Percentile normalization provides robust enhancement against outliers
- Numerical stability constants prevent division by zero in index calculations
- Type conversion to float32 ensures adequate precision for calculations
- Comprehensive statistics enable quality assessment and validation
2.4.6 Visualization Functions 📊
Learning Objectives
- Design publication-quality visualization systems
- Implement adaptive layout algorithms for multi-panel displays
- Master colormap selection for scientific data representation
- Create interactive and informative visual narratives
Scientific Visualization Design Principles
Effective satellite data visualization requires careful consideration of:
- Perceptual Uniformity: Colormaps that accurately represent data relationships
- Information Density: Maximum insight per pixel
- Adaptive Layout: Accommodate variable numbers of data layers
- Context Preservation: Maintain spatial and temporal reference information
def plot_band_comparison(
bands: Dict[str, np.ndarray],
rgb: Optional[np.ndarray] = None,
ndvi: Optional[np.ndarray] = None,
title: str = "Multi-band Analysis",
) -> None:
"""
Create comprehensive multi-panel visualization for satellite analysis.
This function demonstrates several visualization principles:
1. Adaptive Layout: Automatically adjusts grid based on available data
2. Consistent Scaling: Uniform treatment of individual bands
3. Specialized Colormaps: Scientific colormaps for different data types
4. Context Information: Titles, colorbars, and interpretive text
Parameters
----------
bands : Dict[str, np.ndarray]
Individual spectral bands to visualize
rgb : Optional[np.ndarray]
True color composite for context
ndvi : Optional[np.ndarray]
Vegetation index with specialized colormap
title : str
Overall figure title
Design Pattern: Facade Pattern for Complex Visualizations
- Simplifies complex matplotlib operations
- Provides consistent visualization interface
- Handles layout complexity automatically
"""
# Calculate layout
n_panels = (
len(bands) + (1 if rgb is not None else 0) + (1 if ndvi is not None else 0)
)
n_cols = min(3, n_panels)
n_rows = (n_panels + n_cols - 1) // n_cols
fig, axes = plt.subplots(n_rows, n_cols, figsize=(5 * n_cols, 4 * n_rows))
if n_panels == 1:
axes = [axes]
elif n_rows > 1:
axes = axes.flatten()
panel_idx = 0
# RGB composite
if rgb is not None:
axes[panel_idx].imshow(rgb)
axes[panel_idx].set_title("RGB Composite", fontweight="bold")
axes[panel_idx].axis("off")
panel_idx += 1
# Individual bands
for band_name, band_data in bands.items():
if panel_idx < len(axes):
normalized = normalize_band(band_data)
axes[panel_idx].imshow(normalized, cmap="gray", vmin=0, vmax=1)
axes[panel_idx].set_title(f"Band: {band_name}", fontweight="bold")
axes[panel_idx].axis("off")
panel_idx += 1
# NDVI with colorbar
if ndvi is not None and panel_idx < len(axes):
im = axes[panel_idx].imshow(ndvi, cmap="RdYlGn", vmin=-0.5, vmax=1.0)
axes[panel_idx].set_title("NDVI", fontweight="bold")
axes[panel_idx].axis("off")
cbar = plt.colorbar(im, ax=axes[panel_idx], shrink=0.6)
cbar.set_label("NDVI Value", rotation=270, labelpad=15)
panel_idx += 1
# Hide unused panels
for idx in range(panel_idx, len(axes)):
axes[idx].axis("off")
plt.suptitle(title, fontsize=14, fontweight="bold")
plt.tight_layout()
plt.show()
Visualization Design Principles
- Adaptive layouts accommodate varying numbers of data layers
- Perceptually uniform colormaps (like RdYlGn for NDVI) accurately represent data relationships
- Consistent normalization enables fair comparison between bands
- Interpretive elements (colorbars, labels) provide context for non-experts
2.4.7 Data Export and Interoperability 💾
Learning Objectives
- Master geospatial data standards (GeoTIFF, CRS, metadata)
- Implement cloud-optimized data formats for scalable access
- Design interoperable workflows for multi-platform analysis
- Ensure data provenance and reproducibility through metadata
Geospatial Data Standards and Interoperability
Modern geospatial workflows require adherence to established standards:
- GeoTIFF: Industry standard for georeferenced raster data
- CRS Preservation: Maintain spatial reference throughout processing
- Metadata Standards: Ensure data provenance and reproducibility
- Cloud Optimization: Structure data for efficient cloud-native access
def save_geotiff(
data: np.ndarray,
output_path: Union[str, Path],
transform,
crs,
band_names: Optional[List[str]] = None,
) -> None:
"""
Export georeferenced data using industry-standard GeoTIFF format.
This function embodies several geospatial best practices:
1. Standards Compliance: Uses OGC-compliant GeoTIFF format
2. Metadata Preservation: Maintains CRS and transform information
3. Compression: Applies lossless compression for efficiency
4. Band Description: Documents spectral band information
Parameters
----------
data : np.ndarray
Data array (2D for single band, 3D for multi-band)
output_path : Union[str, Path]
Output file path
transform : rasterio.transform.Affine
Geospatial transform matrix
crs : rasterio.crs.CRS
Coordinate reference system
band_names : Optional[List[str]]
Descriptive names for each band
Design Pattern: Builder Pattern for Geospatial Data Export
- Constructs complex geospatial files incrementally
- Ensures all required metadata is preserved
- Provides extensible framework for additional metadata
"""
output_path = Path(output_path)
output_path.parent.mkdir(parents=True, exist_ok=True)
# Handle both 2D and 3D arrays
if data.ndim == 2:
count = 1
height, width = data.shape
else:
count, height, width = data.shape
# Write GeoTIFF with comprehensive metadata
with rasterio.open(
output_path,
"w",
driver="GTiff",
height=height,
width=width,
count=count,
dtype=data.dtype,
crs=crs,
transform=transform,
compress="deflate", # Lossless compression
tiled=True, # Cloud-optimized structure
blockxsize=512, # Optimize for cloud access
blockysize=512,
) as dst:
if data.ndim == 2:
dst.write(data, 1)
if band_names:
dst.set_band_description(1, band_names[0])
else:
for i in range(count):
dst.write(data[i], i + 1)
if band_names and i < len(band_names):
dst.set_band_description(i + 1, band_names[i])
logger = logging.getLogger(__name__)
logger.info(f"Saved GeoTIFF: {output_path}")
Geospatial Data Standards
- GeoTIFF with COG optimization ensures cloud-native accessibility
- CRS preservation maintains spatial accuracy across platforms
- Lossless compression reduces storage costs without data loss
- Band descriptions provide metadata for analysis reproducibility
2.4.8 Advanced Workflow Patterns 🚀
Learning Objectives
- Design scalable spatial partitioning strategies for large-scale analysis
- Implement testing frameworks for geospatial data pipelines
- Master parallel processing patterns for satellite data workflows
- Create adaptive processing strategies based on scene characteristics
Scalable Geospatial Processing Architectures
Large-scale satellite analysis requires sophisticated workflow patterns:
- Spatial Partitioning: Divide scenes into manageable processing units
- Adaptive Strategies: Adjust processing based on data characteristics
- Quality Assurance: Automated testing of processing pipelines
- Parallel Execution: Leverage multiple cores/nodes for efficiency
The create_scene_tiles function systematically partitions a geospatial scene (represented by a STAC item) into a grid of smaller tiles for scalable and parallel processing. It takes as input a STAC item and a desired grid size (e.g., 3×3), then:
- Retrieves scene metadata (such as bounding box and area).
- Iterates over the grid dimensions to compute the spatial extent of each tile as a percentage of the scene.
- For each tile, calculates its bounding box and relevant metadata.
- Returns a list of dictionaries, each describing a tile’s spatial boundaries and processing information.
This approach enables efficient parallelization, memory management, and quality control by allowing independent processing and testing of each tile, and is designed to be flexible for different partitioning strategies.
def create_scene_tiles(item, tile_size: Tuple[int, int] = (3, 3)):
"""
Create systematic spatial partitioning for parallel processing workflows.
This tiling approach enables several advanced patterns:
1. Parallel Processing: Independent tiles can be processed simultaneously
2. Memory Management: Process large scenes without loading entirely
3. Quality Control: Test processing on representative tiles first
4. Scalability: Extend to arbitrary scene sizes and processing resources
Parameters
----------
item : pystac.Item
STAC item to partition
tile_size : Tuple[int, int]
Grid dimensions (nx, ny)
Returns
-------
List[Dict]
Tile metadata with bounding boxes and processing information
Design Pattern: Strategy Pattern for Spatial Partitioning
- Provides flexible tiling strategies for different use cases
- Encapsulates spatial mathematics complexity
- Enables systematic quality control and testing
"""
tiles = []
nx, ny = tile_size
scene_info = get_scene_info(item)
logger.info(f"Creating {nx}×{ny} tile grid ({nx * ny} total tiles)")
for i in range(nx):
for j in range(ny):
# Calculate percentage ranges for this tile
x_start = (i / nx) * 100
x_end = ((i + 1) / nx) * 100
y_start = (j / ny) * 100
y_end = ((j + 1) / ny) * 100
# Generate tile bounding box
tile_bbox = get_subset_from_scene(
item, x_range=(x_start, x_end), y_range=(y_start, y_end)
)
# Package tile metadata for processing
tile_info = {
"tile_id": f"{i}_{j}",
"row": j,
"col": i,
"bbox": tile_bbox,
"x_range": (x_start, x_end),
"y_range": (y_start, y_end),
"area_percent": ((x_end - x_start) * (y_end - y_start)) / 100.0,
"processing_priority": "high"
if (i == nx // 2 and j == ny // 2)
else "normal", # Center tile first
}
tiles.append(tile_info)
return tilesTesting functionality
The next code block introduces a function called test_subset_functionality. This function is designed to perform automated quality assurance on geospatial data loading pipelines. It does so by running a series of tests on a small, central subset of a geospatial scene, using a STAC item as input. The function checks that the subset extraction and band loading processes work correctly, verifies that data is actually loaded, and provides informative print statements about the test results. This approach helps catch errors early, ensures that the core data loading functionality is operational before processing larger datasets, and validates performance on a manageable data sample.
def test_subset_functionality(item):
"""
Automated quality assurance for data loading pipelines.
This testing approach demonstrates:
1. Smoke Testing: Verify basic functionality before full processing
2. Representative Sampling: Test with manageable data subset
3. Error Detection: Identify issues early in processing pipeline
4. Performance Validation: Ensure acceptable loading performance
Parameters
----------
item : pystac.Item
STAC item to test
Returns
-------
bool
True if subset functionality is working correctly
Design Pattern: Chain of Responsibility for Quality Assurance
- Implements systematic testing hierarchy
- Provides early failure detection
- Validates core functionality before expensive operations
"""
try:
# Test with small central area (minimal data transfer)
test_bbox = get_subset_from_scene(item, x_range=(40, 60), y_range=(40, 60))
# Load minimal data for testing
test_data = load_sentinel2_bands(
item,
bands=["B04"], # Single band reduces test time
subset_bbox=test_bbox,
max_retries=2,
)
if "B04" in test_data:
return True
else:
logger.error(f"Subset test failed: no data returned")
return False
except Exception as e:
logger.error(f"Subset test failed: {str(e)[:50]}...")
return False2.5 Summary: Your Geospatial AI Toolkit
You now have a comprehensive, production-ready toolkit with:
Core Capabilities:
- 🔐 Enterprise Authentication: Secure, scalable API access patterns
- 🔍 Intelligent Data Discovery: Cloud-native search with optimization
- 📥 Memory-Efficient Loading: Robust data access with subsetting
- 📐 Spatial Processing: Percentage-based, reproducible operations
- 🔬 Spectral Analysis: Publication-quality processing pipelines
- 📊 Scientific Visualization: Adaptive, informative displays
- 💾 Standards-Compliant Export: Interoperable data formats
- 🚀 Scalable Workflows: Parallel processing and quality assurance
Design Philosophy:
Each function embodies software engineering best practices:
- Error Handling: Graceful degradation and informative error messages
- Composability: Functions work together in complex workflows
- Extensibility: Easy to modify and extend for new requirements
- Documentation: Clear examples and architectural reasoning
Ready for Production:
These functions are designed for real-world deployment:
- Scalability: Handle datasets from small studies to global analysis
- Reliability: Robust error handling and recovery mechanisms
- Performance: Memory-efficient algorithms and cloud optimization
- Maintainability: Clear code structure and comprehensive documentation
Troubleshooting:
- Systematic tiling enables parallel processing of large datasets
- Quality assurance testing prevents failures in production workflows
- Adaptive processing priorities optimize resource utilization
- Metadata packaging supports complex workflow orchestration
3. Understanding STAC APIs and Cloud-Native Geospatial Architecture
Learning Objectives
By the end of this section, you will:
Understand the STAC specification and its role in modern geospatial architecture Connect to cloud-native data catalogs with proper authentication Explore available satellite datasets and their characteristics Design robust data discovery workflows for production systems
The STAC Revolution: From Data Downloads to Cloud-Native Discovery
STAC (SpatioTemporal Asset Catalog) represents a fundamental shift in how we access geospatial data. Instead of downloading entire datasets (often terabytes), STAC enables intelligent, on-demand access to exactly the data you need.
Why STAC Matters for Geospatial AI
Traditional satellite data distribution faced several challenges. Users were required to download and store massive datasets locally, leading to significant storage bottlenecks. There was no standardized way to search across different providers, making data discovery difficult. Before analysis could begin, heavy preprocessing was often necessary, creating additional barriers. Furthermore, tracking data lineage and updates was challenging, complicating version control.
STAC addresses these issues by enabling federated discovery, allowing users to search across multiple data providers through a unified interface. It supports lazy loading, so only the necessary spatial and temporal subsets are accessed. The use of rich, standardized metadata enables intelligent filtering of data. Additionally, STAC is optimized for the cloud, providing direct access to analysis-ready data stored remotely.
STAC Architecture Components
The STAC architecture is composed of several key elements. STAC Items represent individual scenes or data granules, each described with standardized metadata. These items are grouped into STAC Collections, which organize related items, such as all Sentinel-2 data. Collections and items are further structured within STAC Catalogs, creating a hierarchical organization that enables efficient navigation and discovery. Access to these resources is provided through STAC APIs, which are RESTful interfaces designed for searching and retrieving geospatial data.
Practical STAC Connection: Microsoft Planetary Computer
Microsoft Planetary Computer hosts one of the world’s largest STAC catalogs, providing free access to petabytes of environmental data. Let’s establish a robust connection and explore available datasets.
Testing STAC Connectivity and Catalog Discovery
This connection test demonstrates several important concepts for production geospatial systems:
# Connect to STAC catalog
try:
catalog = Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=pc.sign_inplace
)
logger.info("Connected to Planetary Computer STAC API")
# Get catalog information
try:
catalog_info = catalog.get_self()
logger.info(f"Catalog: {catalog_info.title}")
except Exception:
logger.info("Basic connection successful")
# Explore key satellite datasets
satellite_collections = {
'sentinel-2-l2a': 'Sentinel-2 Level 2A (10m optical)',
'landsat-c2-l2': 'Landsat Collection 2 Level 2 (30m optical)',
'sentinel-1-grd': 'Sentinel-1 SAR (radar)',
'naip': 'NAIP (1m aerial imagery)'
}
available_collections = []
for collection_id, description in satellite_collections.items():
try:
collection = catalog.get_collection(collection_id)
available_collections.append(collection_id)
logger.info(f"Available: {description}")
except Exception:
logger.warning(f"Not accessible: {description}")
logger.info(f"Accessible collections: {len(available_collections)}/{len(satellite_collections)}")
except Exception as e:
logger.error(f"\nSTAC connection failed: {str(e)}")2025-10-09 12:58:29,179 - INFO - Connected to Planetary Computer STAC API
2025-10-09 12:58:29,181 - INFO - Basic connection successful
2025-10-09 12:58:30,329 - INFO - Available: Sentinel-2 Level 2A (10m optical)
2025-10-09 12:58:30,528 - INFO - Available: Landsat Collection 2 Level 2 (30m optical)
2025-10-09 12:58:30,936 - INFO - Available: Sentinel-1 SAR (radar)
2025-10-09 12:58:31,137 - INFO - Available: NAIP (1m aerial imagery)
2025-10-09 12:58:31,139 - INFO - Accessible collections: 4/4Connection Troubleshooting
If you encounter connection issues, first verify your internet connectivity and check your firewall settings. Keep in mind that anonymous users have lower API rate limits than authenticated users, which can also cause problems. You should also check the Planetary Computer status page to see if there are any ongoing outages. Finally, make sure you have the latest versions of both the pystac-client and planetary-computer packages installed.
The connection process demonstrates real-world challenges in building production geospatial systems.
Understanding Collection Metadata and Selection Criteria
Each STAC collection contains rich metadata that helps you choose the right dataset for your analysis. Let’s explore how to make informed decisions about which satellite data to use:
4. Spatial Analysis Design - Defining Areas of Interest
Learning Objectives
By the end of this section, you will be able to understand coordinate systems and bounding box conventions in geospatial analysis, design effective study areas based on analysis objectives and data characteristics, create interactive maps for spatial context and validation, and apply best practices for reproducible spatial analysis workflows.
The Art and Science of Spatial Scope Definition
Defining your Area of Interest (AOI) is a critical design decision that influences several aspects of your analysis. The size of the area determines the amount of data you need to process and store. The validity of your analysis depends on how well your study boundaries align with relevant ecological or administrative regions. The location of your AOI affects satellite revisit patterns and data availability, and the way you define your area can impact processing efficiency, such as the choice of optimal tile sizes for your workflow.
Coordinate Systems and Bounding Box Conventions
For our AOI definition, we will use the WGS84 geographic coordinate system (EPSG:4326). In this system, longitude (X) represents the east-west position and ranges from -180° to +180°, with negative values indicating west. Latitude (Y) represents the north-south position and ranges from -90° to +90°, with negative values indicating south. Bounding boxes are formatted as [west, south, east, north], corresponding to (min_x, min_y, max_x, max_y).
Study Area Selection: Santa Barbara Region
We’ll use the Santa Barbara region as our exemplar study region because it features a diverse mix of coastal, urban, mountainous, and agricultural environments. The region is characterized by dynamic processes such as coastal dynamics, wildfire activity, vegetation changes, and urban-wildland interface transitions. It also benefits from frequent satellite coverage and presents geographic complexity, including the Santa Ynez Mountains, Channel Islands, agricultural valleys, and varied coastal ecosystems.
Designing Area of Interest (AOI) for Geospatial Analysis
This demonstrates spatial scope definition for satellite-based studies. We’ll work with the Santa Barbara region as our primary study area.
# Step 3A: Define Area of Interest with Geographic Reasoning
# Primary study area: Santa Barbara Region
# Coordinates chosen to encompass the greater Santa Barbara County coastal region
santa_barbara_bbox = [-120.5, 34.3, -119.5, 34.7] # [west, south, east, north]
# Import required libraries for spatial calculations
from shapely.geometry import box
import os
# Create geometry object for area calculations
aoi_geom = box(*santa_barbara_bbox)
# Calculate basic spatial metrics
area_degrees = aoi_geom.area
# Approximate conversion to kilometers (valid for mid-latitudes)
center_lat = (santa_barbara_bbox[1] + santa_barbara_bbox[3]) / 2
lat_correction = np.cos(np.radians(center_lat))
area_km2 = area_degrees * (111.32 ** 2) * lat_correction # 1 degree ≈ 111.32 km
logger.info(f"AOI: Santa Barbara County ({area_km2:.0f} km²)")
# Provide alternative study areas for different research interests
alternative_aois = {
"San Francisco Bay Area": {
"bbox": [-122.5, 37.3, -121.8, 38.0],
"focus": "Urban growth, water dynamics, mixed land use",
"challenges": "Fog and cloud cover in summer"
},
"Los Angeles Basin": {
"bbox": [-118.7, 33.7, -118.1, 34.3],
"focus": "Urban heat islands, air quality, sprawl patterns",
"challenges": "Frequent clouds, complex topography"
},
"Central Valley Agriculture": {
"bbox": [-121.5, 36.0, -120.0, 37.5],
"focus": "Crop monitoring, irrigation patterns, drought",
"challenges": "Seasonal variations, haze"
},
"Channel Islands": {
"bbox": [-120.5, 33.9, -119.0, 34.1],
"focus": "Island ecology, marine-terrestrial interface, conservation",
"challenges": "Marine layer, limited ground truth"
}
}2025-10-09 12:58:31,157 - INFO - AOI: Santa Barbara County (4085 km²)Interactive Mapping for Spatial Context and Validation
Creating interactive maps serves several important purposes in geospatial analysis, such as providing spatial context to understand the geographic setting and features, validating that the area of interest (AOI) encompasses the intended study features, supporting stakeholder communication through visual representation for project discussions, and enabling quality assurance by helping to detect coordinate errors or unrealistic extents.
Creating Interactive Map for Spatial Context:
This demonstrates best practices for geospatial visualization with multiple basemap options.
# Step 3B: Create Interactive Map with Multiple Basemap Options
# Calculate map center for optimal display
center_lat = (santa_barbara_bbox[1] + santa_barbara_bbox[3]) / 2
center_lon = (santa_barbara_bbox[0] + santa_barbara_bbox[2]) / 2
# Initialize folium map with appropriate zoom level
# Zoom level chosen to show entire AOI while maintaining detail
m = folium.Map(
location=[center_lat, center_lon],
zoom_start=9, # Optimal for metropolitan area viewing
tiles='OpenStreetMap'
)
# Add diverse basemap options for different analysis contexts
basemap_options = {
'CartoDB positron': {
'layer': folium.TileLayer('CartoDB positron', name='Clean Basemap'),
'use_case': 'Data overlay visualization, presentations'
},
'CartoDB dark_matter': {
'layer': folium.TileLayer('CartoDB dark_matter', name='Dark Theme'),
'use_case': 'Night mode, reducing eye strain'
},
'Esri World Imagery': {
'layer': folium.TileLayer(
tiles='https://server.arcgisonline.com/ArcGIS/rest/services/World_Imagery/MapServer/tile/{z}/{y}/{x}',
attr='Esri', name='Satellite Imagery', overlay=False, control=True
),
'use_case': 'Ground truth validation, visual interpretation'
},
'OpenTopoMap': {
'layer': folium.TileLayer(
tiles='https://{s}.tile.opentopomap.org/{z}/{x}/{y}.png',
name='Topographic (OpenTopoMap)',
attr='Map data: © OpenStreetMap contributors, SRTM | Map style: © OpenTopoMap (CC-BY-SA)',
overlay=False,
control=True
),
'use_case': 'Elevation context, watershed analysis'
}
}
for name, info in basemap_options.items():
info['layer'].add_to(m)
# Add AOI boundary with informative styling
aoi_bounds = [[santa_barbara_bbox[1], santa_barbara_bbox[0]], # southwest corner
[santa_barbara_bbox[3], santa_barbara_bbox[2]]] # northeast corner
folium.Rectangle(
bounds=aoi_bounds,
color='red',
weight=3,
fill=True,
fillOpacity=0.1,
popup=folium.Popup(
f"""
<div style="font-family: Arial; width: 300px;">
<h4>📊 Study Area Details</h4>
<b>Region:</b> Santa Barbara County Coastal Region<br>
<b>Coordinates:</b> {santa_barbara_bbox}<br>
<b>Area:</b> {area_km2:.0f} km²<br>
<b>Purpose:</b> Geospatial AI Training<br>
<b>Data Type:</b> Sentinel-2 Optical<br>
</div>
""",
max_width=350
),
tooltip="Study Area Boundary - Click for details"
).add_to(m)
# Add geographic reference points with contextual information
reference_locations = [
{
"name": "Santa Barbara",
"coords": [34.4208, -119.6982],
"description": "Coastal city, urban-wildland interface",
"icon": "building",
"color": "blue"
},
{
"name": "UCSB",
"coords": [34.4140, -119.8489],
"description": "University campus, research facilities",
"icon": "graduation-cap",
"color": "green"
},
{
"name": "Goleta",
"coords": [34.4358, -119.8276],
"description": "Tech corridor, agricultural transition zone",
"icon": "microchip",
"color": "purple"
},
{
"name": "Montecito",
"coords": [34.4358, -119.6376],
"description": "Wildfire-prone, high-value urban area",
"icon": "fire",
"color": "red"
}
]
for location in reference_locations:
folium.Marker(
location=location["coords"],
popup=folium.Popup(
f"""
<div style="font-family: Arial;">
<h4>{location['name']}</h4>
<b>Coordinates:</b> {location['coords'][0]:.4f}, {location['coords'][1]:.4f}<br>
<b>Context:</b> {location['description']}<br>
<b>Role in Analysis:</b> Geographic reference point
</div>
""",
max_width=250
),
tooltip=f"{location['name']} - {location['description']}",
icon=folium.Icon(
color=location['color'],
icon=location['icon'],
prefix='fa'
)
).add_to(m)
# Add measurement and interaction tools for analysis
# Measurement tool for distance/area calculations
from folium.plugins import MeasureControl
measure_control = MeasureControl(
primary_length_unit='kilometers',
primary_area_unit='sqkilometers',
secondary_length_unit='miles',
secondary_area_unit='sqmiles'
)
m.add_child(measure_control)
logger.debug("Added measurement tool for distance/area calculations")
# Fullscreen capability for detailed examination
from folium.plugins import Fullscreen
Fullscreen(
position='topright',
title='Full Screen Mode',
title_cancel='Exit Full Screen',
force_separate_button=True
).add_to(m)
logger.debug("Added fullscreen mode capability")
# Layer control for basemap switching
layer_control = folium.LayerControl(
position='topright',
collapsed=False
)
layer_control.add_to(m)
# Display the map
mMake this Notebook Trusted to load map: File -> Trust Notebook
AOI Design Best Practices
Size Considerations:
When defining your Area of Interest (AOI), consider that an area too small may miss important spatial patterns or edge effects, while an area too large can increase processing time and may include irrelevant regions. Aim for a balance that ensures computational efficiency without sacrificing analytical completeness.
Boundary Alignment:
AOI boundaries can be aligned with ecological features such as watersheds, ecoregions, or habitat boundaries; with administrative units like counties, states, or protected areas; or with sensor-based divisions such as satellite tile boundaries and processing units. Choose the alignment that best fits your study objectives.
Temporal Considerations:
Ensure your AOI captures relevant seasonal dynamics and accounts for both historical and projected changes in the study area. Also, verify that data coverage is consistent across your intended temporal study period.
Validating Your AOI Selection
Before proceeding with data acquisition, confirm that your AOI is well-matched to your analysis objectives.
5. Intelligent Satellite Scene Discovery and Selection
5.1 Intelligent Satellite Scene Discovery
Selecting appropriate satellite imagery is a multi-faceted challenge that requires balancing several key factors: temporal coverage (recent vs. historical data), data quality (cloud cover, sensor conditions, processing artifacts), spatial coverage (ensuring your AOI is fully captured), and the processing level of the data (raw vs. analysis-ready products). Relying on a single search strategy often leads to missed opportunities or suboptimal results, especially when data availability is limited by weather or acquisition schedules.
To address these challenges, a robust approach involves designing and implementing multi-strategy search patterns. This means systematically applying a sequence of search strategies, each with progressively relaxed criteria—such as expanding the temporal window or increasing the allowable cloud cover. By doing so, you maximize the chances of finding suitable imagery while still prioritizing the highest quality data available. This method is widely used in operational geospatial systems to ensure reliable and efficient satellite scene discovery, even under less-than-ideal conditions.
By the end of this section, you will be able to design robust, multi-strategy search workflows for satellite data discovery, understand how quality filters and temporal windows affect data availability, implement fallback mechanisms to guarantee reliable data access, and evaluate scene metadata to select the most appropriate imagery for your analysis.
# Step 4A: Implement Robust Multi-Strategy Scene Discovery
from datetime import datetime, timedelta
# Strategy 1: Dynamic temporal window based on current date
current_date = datetime.now()
# Define multiple search strategies with different trade-offs
# Each strategy balances data quality against data availability
search_strategies = [
{
"name": "Optimal Quality",
"date_range": "2024-06-01/2024-09-30",
"cloud_max": 20,
"description": "Recent summer data with excellent atmospheric conditions",
"priority": "Best for analysis quality",
"trade_offs": "May have limited availability"
},
{
"name": "Good Quality",
"date_range": "2024-03-01/2024-08-31",
"cloud_max": 35,
"description": "Extended seasonal window with good conditions",
"priority": "Balance of quality and availability",
"trade_offs": "Some atmospheric interference"
},
{
"name": "Acceptable Quality",
"date_range": "2023-09-01/2024-11-30",
"cloud_max": 50,
"description": "Broader temporal and quality window",
"priority": "Reliable data availability",
"trade_offs": "May require additional preprocessing"
},
{
"name": "Fallback Option",
"date_range": "2023-01-01/2024-12-31",
"cloud_max": 75,
"description": "Maximum temporal window, relaxed quality constraints",
"priority": "Guaranteed data access",
"trade_offs": "Significant cloud contamination possible"
}
]
# Execute search strategies in order of preference
scenes = []
successful_strategy = None
for i, strategy in enumerate(search_strategies, 1):
try:
# Use our optimized search function with current strategy parameters
temp_scenes = search_sentinel2_scenes(
bbox=santa_barbara_bbox,
date_range=strategy["date_range"],
cloud_cover_max=strategy["cloud_max"],
limit=100 # Generous limit for selection flexibility
)
if temp_scenes:
scenes = temp_scenes
successful_strategy = strategy
break
except Exception as e:
logger.warning(f"Search failed for {strategy['name']}: {str(e)[:80]}")
continue
# Validate search results
if not scenes:
logger.error(f"Scene discovery failed after trying all {len(search_strategies)} strategies")
raise Exception("Critical failure in scene discovery")2025-10-09 12:58:33,250 - INFO - Found 40 Sentinel-2 scenes (cloud cover < 20%)5.2 Scene Quality Assessment and Selection
Once we have candidate scenes, we need to systematically evaluate and select the best option:
Performing Comprehensive Scene Quality Assessment:
This demonstrates multi-criteria decision making for satellite data selection using cloud cover, acquisition date, and other quality metrics.
# Step 4B: Intelligent Scene Selection Based on Multiple Quality Criteria
# Sort scenes by multiple quality criteria
# Primary: cloud cover (lower is better)
# Secondary: date (more recent is better)
scenes_with_scores = []
for scene in scenes:
props = scene.properties
# Extract key quality metrics
cloud_cover = props.get('eo:cloud_cover', 100)
date_str = props.get('datetime', '').split('T')[0]
scene_date = datetime.strptime(date_str, '%Y-%m-%d')
days_old = (current_date - scene_date).days
# Calculate composite quality score (lower is better)
# Weight factors: cloud cover (70%), recency (30%)
cloud_score = cloud_cover # 0-100 scale
recency_score = min(days_old / 30, 100) # Normalize to 0-100, cap at 100
quality_score = (0.7 * cloud_score) + (0.3 * recency_score)
scene_info = {
'scene': scene,
'date': date_str,
'cloud_cover': cloud_cover,
'days_old': days_old,
'quality_score': quality_score,
'tile_id': props.get('sentinel:grid_square', 'Unknown'),
'platform': props.get('platform', 'Sentinel-2')
}
scenes_with_scores.append(scene_info)
# Sort by quality score (best first)
scenes_with_scores.sort(key=lambda x: x['quality_score'])
# Display top candidates for educational purposes
logger.info("Top 5 Scene Candidates (ranked by quality score):")
for i, scene_info in enumerate(scenes_with_scores[:5], 1):
logger.debug(f"{i}. {scene_info['date']} - Cloud: {scene_info['cloud_cover']:.1f}%, Age: {scene_info['days_old']} days, Score: {scene_info['quality_score']:.1f}")
if i == 1:
logger.info(f"Selected optimal scene: {scene_info['date']}")
# Select the best scene
best_scene_info = scenes_with_scores[0]
best_scene = best_scene_info['scene']
logger.info(f"Optimal scene selected: {best_scene_info['date']} ({best_scene_info['cloud_cover']:.1f}% cloud cover, {best_scene_info['platform']}, Tile: {best_scene_info['tile_id']})")
# Validate scene completeness for required analysis
logger.info("Validating scene data completeness")
required_bands = ['B02', 'B03', 'B04', 'B08'] # Blue, Green, Red, NIR
available_bands = list(best_scene.assets.keys())
spectral_bands = [b for b in available_bands if b.startswith('B') and len(b) <= 3]
logger.debug(f"Available spectral bands: {len(spectral_bands)}, Required: {required_bands}")
missing_bands = [b for b in required_bands if b not in available_bands]
if missing_bands:
logger.warning(f"Missing critical bands: {missing_bands} - this may limit analysis capabilities")
# Check for alternative bands
alternative_mapping = {'B02': 'blue', 'B03': 'green', 'B04': 'red', 'B08': 'nir'}
alternatives_found = []
for missing in missing_bands:
alt_name = alternative_mapping.get(missing, missing.lower())
if alt_name in available_bands:
alternatives_found.append((missing, alt_name))
if alternatives_found:
logger.info(f"Found alternative band names: {alternatives_found}")
else:
logger.info("All required bands available")
# Additional quality checks
extra_bands = [b for b in spectral_bands if b not in required_bands]
if extra_bands:
logger.debug(f"Bonus bands available: {extra_bands[:5]}{'...' if len(extra_bands) > 5 else ''} (enable advanced spectral analysis)")
logger.info("Scene validation complete - ready for data loading")
# Quick connectivity test using our helper function
logger.info("Performing pre-flight connectivity test")
connectivity_test = test_subset_functionality(best_scene)
if connectivity_test:
logger.info("Data access confirmed - all systems ready")
else:
logger.warning("Connectivity issues detected - will attempt full download with fallback mechanisms")2025-10-09 12:58:33,265 - INFO - Top 5 Scene Candidates (ranked by quality score):
2025-10-09 12:58:33,266 - INFO - Selected optimal scene: 2024-08-13
2025-10-09 12:58:33,266 - INFO - Optimal scene selected: 2024-08-13 (0.0% cloud cover, Sentinel-2B, Tile: Unknown)
2025-10-09 12:58:33,267 - INFO - Validating scene data completeness
2025-10-09 12:58:33,267 - INFO - All required bands available
2025-10-09 12:58:33,268 - INFO - Scene validation complete - ready for data loading
2025-10-09 12:58:33,268 - INFO - Performing pre-flight connectivity test
2025-10-09 12:58:45,740 - INFO - Successfully loaded 1 bands: ['B04']
2025-10-09 12:58:45,741 - INFO - Data access confirmed - all systems readyScene selection for geospatial analysis should prioritize several key quality criteria. Cloud cover is the most important factor, as it directly affects data usability. Temporal relevance is also critical; more recent data better reflects current conditions. The processing level matters as well—Level 2A data, for example, provides atmospheric correction, which is often preferred. Finally, consider spatial coverage, ensuring that the selected scene fully covers the area of interest rather than only partially.
In production workflows, it is important to have fallback strategies in place, such as using multiple search approaches to ensure data availability. Automated selection can be improved by applying standardized quality scoring metrics. Always validate metadata to confirm that all required bands and assets are present, and test connectivity to the data source before starting major processing tasks.
Before loading data, it is helpful to examine the characteristics of the selected Sentinel-2 scene. For example, you can use the eo:cloud_cover property to filter scenes by cloud coverage. Sentinel-2 satellites revisit the same location every five days, so multiple scenes are usually available for a given area. Level 2A data is already atmospherically corrected, which simplifies preprocessing. Be aware that different satellites may use different naming conventions and have varying properties.
A thorough analysis of scene metadata is essential for designing effective workflows. By systematically inventorying available assets and understanding sensor characteristics, you can take full advantage of the rich metadata provided in STAC items and ensure your analysis is both robust and reliable.
# Step 4C: Comprehensive Scene and Sensor Characterization
if 'best_scene' in locals():
scene_props = best_scene.properties
scene_assets = best_scene.assets
# Sentinel-2 spectral band specifications with AI applications
sentinel2_bands = {
'B01': {
'name': 'Coastal/Aerosol',
'wavelength': '443 nm',
'resolution': '60m',
'ai_applications': 'Atmospheric correction, aerosol detection'
},
'B02': {
'name': 'Blue',
'wavelength': '490 nm',
'resolution': '10m',
'ai_applications': 'Water body detection, urban classification'
},
'B03': {
'name': 'Green',
'wavelength': '560 nm',
'resolution': '10m',
'ai_applications': 'Vegetation health, true color composites'
},
'B04': {
'name': 'Red',
'wavelength': '665 nm',
'resolution': '10m',
'ai_applications': 'Vegetation stress, NDVI calculation'
},
'B05': {
'name': 'Red Edge 1',
'wavelength': '705 nm',
'resolution': '20m',
'ai_applications': 'Vegetation analysis, crop type classification'
},
'B06': {
'name': 'Red Edge 2',
'wavelength': '740 nm',
'resolution': '20m',
'ai_applications': 'Advanced vegetation indices, stress detection'
},
'B07': {
'name': 'Red Edge 3',
'wavelength': '783 nm',
'resolution': '20m',
'ai_applications': 'Vegetation biophysical parameters'
},
'B08': {
'name': 'NIR (Near Infrared)',
'wavelength': '842 nm',
'resolution': '10m',
'ai_applications': 'Biomass estimation, water/land separation'
},
'B8A': {
'name': 'NIR Narrow',
'wavelength': '865 nm',
'resolution': '20m',
'ai_applications': 'Refined vegetation analysis'
},
'B09': {
'name': 'Water Vapor',
'wavelength': '945 nm',
'resolution': '60m',
'ai_applications': 'Atmospheric water vapor correction'
},
'B11': {
'name': 'SWIR 1',
'wavelength': '1610 nm',
'resolution': '20m',
'ai_applications': 'Fire detection, soil moisture, geology'
},
'B12': {
'name': 'SWIR 2',
'wavelength': '2190 nm',
'resolution': '20m',
'ai_applications': 'Burn area mapping, mineral detection'
}
}
# Additional data products available in Level 2A
additional_products = {
'SCL': {
'name': 'Scene Classification Layer',
'description': 'Pixel-level land cover classification',
'ai_applications': 'Cloud masking, quality assessment'
},
'AOT': {
'name': 'Aerosol Optical Thickness',
'description': 'Atmospheric aerosol content',
'ai_applications': 'Atmospheric correction validation'
},
'WVP': {
'name': 'Water Vapor Pressure',
'description': 'Columnar water vapor content',
'ai_applications': 'Atmospheric correction, weather analysis'
},
'visual': {
'name': 'True Color Preview',
'description': 'RGB composite for visualization',
'ai_applications': 'Quick visual assessment, presentation'
},
'thumbnail': {
'name': 'Scene Thumbnail',
'description': 'Low-resolution preview image',
'ai_applications': 'Rapid quality screening'
}
}
# Scene technical specifications
acquisition_date = scene_props.get('datetime', 'Unknown').split('T')[0]
platform = scene_props.get('platform', 'Unknown')
cloud_cover = scene_props.get('eo:cloud_cover', 0)
tile_id = scene_props.get('sentinel:grid_square', 'Unknown')
logger.info(f"Scene: {platform} {acquisition_date}, Cloud: {cloud_cover:.1f}%, Tile: {tile_id}")
# Inventory available spectral bands
available_spectral = []
available_products = []
for band_id, info in sentinel2_bands.items():
if band_id in scene_assets:
available_spectral.append(band_id)
logger.debug(f"Available: {band_id} ({info['name']}, {info['resolution']})")
for product_id, info in additional_products.items():
if product_id in scene_assets:
available_products.append(product_id)
logger.debug(f"Available product: {product_id} - {info['name']}")
# Analysis readiness assessment
core_bands = ['B02', 'B03', 'B04', 'B08'] # Essential for basic analysis
advanced_bands = ['B05', 'B06', 'B07', 'B8A', 'B11', 'B12'] # For advanced analysis
core_available = sum(1 for band in core_bands if band in available_spectral)
advanced_available = sum(1 for band in advanced_bands if band in available_spectral)
# Analysis readiness assessment
logger.info(f"Bands available: {core_available}/{len(core_bands)} core, {advanced_available}/{len(advanced_bands)} advanced")
logger.info(f"Additional products: {len(available_products)}")
# Determine analysis capabilities
if core_available == len(core_bands):
analysis_capabilities = ["NDVI calculation", "True color visualization", "Basic land cover classification"]
if 'B11' in available_spectral and 'B12' in available_spectral:
analysis_capabilities.extend(["Fire detection", "Soil moisture analysis"])
if advanced_available >= 4:
analysis_capabilities.extend(["Advanced vegetation indices", "Crop type classification"])
if 'SCL' in available_products:
analysis_capabilities.append("Automated cloud masking")
logger.info(f"Analysis ready: {len(analysis_capabilities)} capabilities enabled")
else:
missing_core = [band for band in core_bands if band not in available_spectral]
logger.warning(f"Limited analysis: missing core bands {missing_core}")
# Store technical metadata
crs_info = f"EPSG:{scene_props['proj:epsg']}" if 'proj:epsg' in scene_props else "UTM"
utm_zone = scene_props.get('sentinel:utm_zone', 'Unknown')
logger.info(f"Metadata: {crs_info}, UTM zone {utm_zone}, 16-bit COG format")
else:
logger.warning("No optimal scene selected - cannot perform metadata analysis")2025-10-09 12:58:45,757 - INFO - Scene: Sentinel-2B 2024-08-13, Cloud: 0.0%, Tile: Unknown
2025-10-09 12:58:45,758 - INFO - Bands available: 4/4 core, 6/6 advanced
2025-10-09 12:58:45,758 - INFO - Additional products: 4
2025-10-09 12:58:45,758 - INFO - Analysis ready: 8 capabilities enabled
2025-10-09 12:58:45,758 - INFO - Metadata: UTM, UTM zone Unknown, 16-bit COG formatSentinel-2 for AI Applications
Sentinel-2 is well-suited for geospatial AI due to its 13 multi-spectral bands spanning the visible to shortwave infrared range. The satellite offers a high revisit frequency of every 5 days, enabling temporal analysis. Its moderate spatial resolution of 10 to 20 meters is optimal for landscape-scale AI tasks. Sentinel-2 data is freely accessible under an open data policy, which supports large-scale model training. The standardized Level 2A processing ensures consistent data quality, and global coverage provides uniform data characteristics worldwide.
For AI applications, Sentinel-2 offers several advantages. The large data volume supports robust model development and training. The scene classification layer can be used as ground truth for validation. Time series data enables the development of sequence models, and the availability of multiple spatial resolutions allows for hierarchical learning approaches.
Now let’s examine the scene’s geographic characteristics and proceed to data loading.
6. Production-Grade Satellite Data Loading and Processing
Learning Objectives
By the end of this section, you will be able to implement memory-efficient satellite data loading with intelligent subsetting, design adaptive processing strategies based on scene characteristics, create robust error handling for network-dependent data workflows, and build multi-dimensional datasets suitable for AI and machine learning applications.
6.1 The Challenge of Large-Scale Satellite Data Loading
Modern satellite scenes can exceed 1GB in size, which requires careful planning for data loading and processing. Efficient memory management is necessary to avoid loading unnecessary data into RAM. Network efficiency is also important to minimize data transfer while maintaining analysis quality. Processing strategies should be adaptive, adjusting to the size and characteristics of each scene. Additionally, workflows must be resilient to network interruptions and data access failures.
6.2 Intelligent Data Loading Architecture
The following approach demonstrates production-ready patterns used in operational systems. It implements an intelligent satellite data loading pipeline that adapts processing based on scene characteristics, selecting optimal loading strategies according to the scene size and analysis requirements.
# Step 5A: Scene Analysis and Adaptive Subset Strategy Selection
if 'best_scene' in locals():
# Comprehensive scene analysis for optimal loading strategy
scene_info = get_scene_info(best_scene)
logger.info(f"Scene extent: {scene_info['width_km']:.1f}×{scene_info['height_km']:.1f} km ({scene_info['area_km2']:.0f} km²)")
# Adaptive subset strategy based on scene characteristics
# Decision matrix for subset sizing
subset_strategies = {
"large_scene": {
"condition": scene_info['area_km2'] > 5000,
"x_range": (30, 70),
"y_range": (30, 70),
"coverage": 16, # 40% × 40%
"rationale": "Conservative subset for large scenes to manage memory usage",
"description": "middle 40% (large scene optimization)"
},
"medium_scene": {
"condition": scene_info['area_km2'] > 1000,
"x_range": (20, 80),
"y_range": (20, 80),
"coverage": 36, # 60% × 60%
"rationale": "Balanced subset for medium scenes",
"description": "middle 60% (balanced approach)"
},
"small_scene": {
"condition": scene_info['area_km2'] <= 1000,
"x_range": (10, 90),
"y_range": (10, 90),
"coverage": 64, # 80% × 80%
"rationale": "Maximum coverage for small scenes",
"description": "most of scene (small scene - maximize coverage)"
}
}
# Select optimal strategy
selected_strategy = None
for strategy_name, strategy in subset_strategies.items():
if strategy["condition"]:
selected_strategy = strategy
strategy_name_selected = strategy_name
logger.info(f"Selected strategy: {strategy_name} ({strategy['coverage']}% coverage)")
break
# Apply selected subset strategy
x_range, y_range = selected_strategy["x_range"], selected_strategy["y_range"]
subset_bbox = get_subset_from_scene(best_scene, x_range=x_range, y_range=y_range)
# Calculate expected data characteristics
subset_area_km2 = scene_info['area_km2'] * (selected_strategy['coverage'] / 100)
estimated_pixels_10m = subset_area_km2 * 1e6 / (10 * 10) # 10m pixel size
# Log subset characteristics
logger.info(f"Subset: {subset_area_km2:.0f} km², {estimated_pixels_10m:,.0f} pixels, ~{estimated_pixels_10m * 4 * 2 / 1e6:.1f} MB")
# Alternative subset strategies available for experimentation
# Core bands for essential analysis
core_bands = ['B04', 'B03', 'B02', 'B08'] # Red, Green, Blue, NIR
logger.info(f"Selected {len(core_bands)} core bands for RGB and NDVI analysis")
else:
logger.warning("No optimal scene available - using default configuration")
core_bands = ['B04', 'B03', 'B02', 'B08'] # Default selection
subset_bbox = None2025-10-09 12:58:45,767 - INFO - Scene extent: 112.2×112.7 km (12646 km²)
2025-10-09 12:58:45,767 - INFO - Selected strategy: large_scene (16% coverage)
2025-10-09 12:58:45,767 - INFO - Subset: 2023 km², 20,233,972 pixels, ~161.9 MB
2025-10-09 12:58:45,768 - INFO - Selected 4 core bands for RGB and NDVI analysis6.3 High-Performance Data Loading Implementation
Now we’ll implement the actual data loading with comprehensive error handling and performance monitoring:
Executing Production-Grade Data Loading:
This demonstrates enterprise-level error handling and performance optimization with comprehensive pre-loading validation.
# Step 5B: Execute Robust Data Loading with Performance Monitoring
if 'best_scene' in locals() and 'subset_bbox' in locals():
# Pre-loading validation and preparation
logger.info(f"Loading scene {best_scene.id}: {len(core_bands)} bands, ~{estimated_pixels_10m * len(core_bands) * 2 / 1e6:.1f} MB")
# Enhanced loading with comprehensive monitoring
loading_start_time = time.time()
try:
band_data = load_sentinel2_bands(
best_scene,
bands=core_bands,
subset_bbox=subset_bbox,
max_retries=5
)
loading_duration = time.time() - loading_start_time
transfer_rate = (estimated_pixels_10m * len(core_bands) * 2 / 1e6) / loading_duration
logger.info(f"Data loading successful: {loading_duration:.1f}s, {transfer_rate:.1f} MB/s")
except Exception as loading_error:
loading_duration = time.time() - loading_start_time
logger.error(f"Data loading failed after {loading_duration:.1f}s: {str(loading_error)[:80]}")
# Fallback 1: Try without subset
try:
band_data = load_sentinel2_bands(
best_scene,
bands=core_bands,
subset_bbox=None,
max_retries=3
)
logger.info("Full scene loading successful")
subset_bbox = None
except Exception as full_scene_error:
logger.warning(f"Full scene loading failed: {str(full_scene_error)[:80]}")
# Fallback 2: Reduce band count
try:
essential_bands = ['B04', 'B08'] # Minimum for NDVI
band_data = load_sentinel2_bands(
best_scene,
bands=essential_bands,
subset_bbox=subset_bbox,
max_retries=3
)
core_bands = essential_bands
logger.info(f"Reduced band loading successful ({len(essential_bands)} bands)")
except Exception as reduced_error:
logger.error("All loading strategies failed - creating synthetic data")
# Create realistic synthetic data for educational continuity
synthetic_size = (1000, 1000)
band_data = {
'B04': np.random.randint(1000, 4000, synthetic_size, dtype=np.uint16),
'B03': np.random.randint(1000, 4000, synthetic_size, dtype=np.uint16),
'B02': np.random.randint(1000, 4000, synthetic_size, dtype=np.uint16),
'B08': np.random.randint(2000, 6000, synthetic_size, dtype=np.uint16),
'transform': None,
'crs': None,
'bounds': subset_bbox if subset_bbox else santa_barbara_bbox,
'scene_id': 'SYNTHETIC_DEMO',
'date': '2024-01-01'
}
logger.info(f"Synthetic data created: {synthetic_size[0]}×{synthetic_size[1]} pixels")
else:
# Fallback for educational purposes
logger.info("No scene available - creating educational synthetic dataset")
synthetic_size = (800, 800)
band_data = {
'B04': np.random.randint(1000, 4000, synthetic_size, dtype=np.uint16),
'B03': np.random.randint(1000, 4000, synthetic_size, dtype=np.uint16),
'B02': np.random.randint(1000, 4000, synthetic_size, dtype=np.uint16),
'B08': np.random.randint(2000, 6000, synthetic_size, dtype=np.uint16),
'transform': None,
'crs': None,
'bounds': [-122.5, 37.7, -122.35, 37.85],
'scene_id': 'EDUCATIONAL_DEMO',
'date': '2024-01-01'
}
core_bands = ['B04', 'B03', 'B02', 'B08']
subset_bbox = None
logger.info(f"Educational dataset ready: {synthetic_size[0]}×{synthetic_size[1]} pixels")2025-10-09 12:58:45,777 - INFO - Loading scene S2B_MSIL2A_20240813T183919_R070_T11SKU_20240813T224159: 4 bands, ~161.9 MB
2025-10-09 13:04:26,664 - INFO - Successfully loaded 4 bands: ['B04', 'B03', 'B02', 'B08']
2025-10-09 13:04:26,664 - INFO - Data loading successful: 340.9s, 0.5 MB/s6.4 Comprehensive Data Validation and Quality Assessment
After loading, we must validate data quality and completeness before proceeding with analysis:
Performing Comprehensive Data Validation:
This demonstrates production-level quality assurance for satellite data including validation of data loading success and quality metrics.
# Step 5C: Comprehensive Data Validation and Quality Assessment
# Validate successful data loading
if 'band_data' in locals() and band_data:
# Extract loaded bands and metadata
available_bands = [b for b in core_bands if b in band_data and isinstance(band_data[b], np.ndarray)]
# Extract georeferencing information
transform = band_data.get('transform', None)
crs = band_data.get('crs', None)
bounds = band_data.get('bounds', subset_bbox if 'subset_bbox' in locals() else santa_barbara_bbox)
scene_id = band_data.get('scene_id', 'Unknown')
acquisition_date = band_data.get('date', 'Unknown')
logger.info(f"Loaded {len(available_bands)}/{len(core_bands)} bands: {available_bands}")
logger.info(f"Scene: {scene_id} ({acquisition_date})")
# Quality assessment
band_stats_summary = {}
for band_name in available_bands:
if band_name in band_data:
stats = calculate_band_statistics(band_data[band_name], band_name)
band_stats_summary[band_name] = stats
# Quality flags
quality_flags = []
if stats['valid_pixels'] < stats['total_pixels'] * 0.95:
quality_flags.append("invalid pixels")
if stats['std'] < 10:
quality_flags.append("low variance")
if stats['max'] > 10000:
quality_flags.append("possible saturation")
quality_status = "; ".join(quality_flags) if quality_flags else "normal"
logger.info(f"{band_name}: range [{stats['min']:.0f}, {stats['max']:.0f}], quality: {quality_status}")
# Cross-band validation
if len(available_bands) >= 2:
shapes = [band_data[band].shape for band in available_bands]
consistent_shape = all(shape == shapes[0] for shape in shapes)
logger.info(f"Spatial consistency: {'OK' if consistent_shape else 'WARNING'} shape {shapes[0] if consistent_shape else 'mixed'}")
# Check for reasonable spectral relationships
if 'B04' in available_bands and 'B08' in available_bands:
ndvi_sample = calculate_ndvi(band_data['B08'][:100, :100], band_data['B04'][:100, :100])
ndvi_mean = np.nanmean(ndvi_sample)
# NDVI sanity check
if -1 <= ndvi_mean <= 1:
logger.info(f"NDVI validation passed: mean = {ndvi_mean:.3f}")
else:
logger.warning(f"NDVI anomaly detected: mean = {ndvi_mean:.3f}")
# Overall data readiness assessment
readiness_score = 0
readiness_criteria = {
'bands_available': len(available_bands) >= 3, # Minimum for RGB
'spatial_consistency': 'consistent_shape' in locals() and consistent_shape,
'valid_pixels': all(stats['valid_pixels'] > stats['total_pixels'] * 0.9 for stats in band_stats_summary.values()),
'spectral_sanity': 'ndvi_mean' in locals() and -1 <= ndvi_mean <= 1
}
readiness_score = sum(readiness_criteria.values())
max_score = len(readiness_criteria)
# Overall data readiness assessment
logger.info(f"Data readiness: {readiness_score}/{max_score} criteria passed")
if readiness_score >= max_score * 0.75:
logger.info("STATUS: READY for analysis - High quality data confirmed")
elif readiness_score >= max_score * 0.5:
logger.warning("STATUS: PROCEED WITH CAUTION - Some quality issues detected")
else:
logger.error("STATUS: QUALITY ISSUES - Consider alternative data sources")
else:
logger.error("Data validation failed - no valid satellite data available")2025-10-09 13:04:26,675 - INFO - Loaded 4/4 bands: ['B04', 'B03', 'B02', 'B08']
2025-10-09 13:04:26,675 - INFO - Scene: S2B_MSIL2A_20240813T183919_R070_T11SKU_20240813T224159 (2024-08-13)
2025-10-09 13:04:27,150 - INFO - B04: range [872, 11120], quality: possible saturation
2025-10-09 13:04:27,600 - INFO - B03: range [969, 10456], quality: possible saturation
2025-10-09 13:04:28,096 - INFO - B02: range [756, 9568], quality: normal
2025-10-09 13:04:28,545 - INFO - B08: range [0, 10704], quality: possible saturation
2025-10-09 13:04:28,545 - INFO - Spatial consistency: OK shape (4626, 4626)
2025-10-09 13:04:28,547 - INFO - NDVI validation passed: mean = 0.310
2025-10-09 13:04:28,547 - INFO - Data readiness: 4/4 criteria passed
2025-10-09 13:04:28,548 - INFO - STATUS: READY for analysis - High quality data confirmed6.5 Creating AI-Ready Multi-Dimensional Datasets
Transform loaded bands into analysis-ready xarray datasets optimized for AI/ML workflows:
Creating AI-Ready Multi-Dimensional Dataset:
This demonstrates data structuring for machine learning applications, transforming raw satellite bands into analysis-ready xarray datasets.
# Step 5D: Build AI-Ready Multi-Dimensional Dataset
if 'band_data' in locals() and band_data and available_bands:
# Get spatial dimensions from first available band
sample_band = band_data[available_bands[0]]
height, width = sample_band.shape
# Dataset characteristics
total_elements = height * width * len(available_bands)
logger.info(f"Dataset: {height}×{width} pixels, {len(available_bands)} bands, {total_elements:,} elements")
# Create sophisticated coordinate system
if bounds and len(bounds) == 4:
# Geographic coordinates (WGS84)
x_coords = np.linspace(bounds[0], bounds[2], width) # Longitude
y_coords = np.linspace(bounds[3], bounds[1], height) # Latitude (north to south)
coord_system = "geographic"
else:
# Pixel coordinates
x_coords = np.arange(width)
y_coords = np.arange(height)
coord_system = "pixel"
logger.debug(f"Coordinates: {coord_system}, X: {x_coords[0]:.4f} to {x_coords[-1]:.4f}, Y: {y_coords[0]:.4f} to {y_coords[-1]:.4f}")
# Build xarray DataArrays with comprehensive metadata
data_arrays = {}
band_metadata = {
'B02': {'name': 'blue', 'wavelength': 490, 'description': 'Blue band (coastal/aerosol)'},
'B03': {'name': 'green', 'wavelength': 560, 'description': 'Green band (vegetation)'},
'B04': {'name': 'red', 'wavelength': 665, 'description': 'Red band (chlorophyll absorption)'},
'B08': {'name': 'nir', 'wavelength': 842, 'description': 'Near-infrared (biomass/structure)'}
}
# Build spectral data arrays
for band_id in available_bands:
if band_id in band_metadata:
metadata = band_metadata[band_id]
band_name = metadata['name']
# Create DataArray with rich metadata
data_arrays[band_name] = xr.DataArray(
band_data[band_id],
dims=['y', 'x'],
coords={
'y': ('y', y_coords, {'long_name': 'Latitude' if coord_system == 'geographic' else 'Y coordinate',
'units': 'degrees_north' if coord_system == 'geographic' else 'pixels'}),
'x': ('x', x_coords, {'long_name': 'Longitude' if coord_system == 'geographic' else 'X coordinate',
'units': 'degrees_east' if coord_system == 'geographic' else 'pixels'})
},
attrs={
'band_id': band_id,
'long_name': metadata['description'],
'wavelength': metadata['wavelength'],
'wavelength_units': 'nanometers',
'units': 'DN',
'valid_range': [0, 10000],
'scale_factor': 1.0,
'add_offset': 0.0
}
)
logger.debug(f"Created DataArray: {band_name} ({metadata['wavelength']}nm)")
# Create comprehensive Dataset
satellite_ds = xr.Dataset(
data_arrays,
attrs={
'title': 'Sentinel-2 Level 2A Surface Reflectance',
'source': f'Scene: {scene_id}',
'acquisition_date': acquisition_date,
'processing_level': 'L2A',
'crs': str(crs) if crs else 'WGS84 (assumed)',
'spatial_resolution': '10 meters',
'coordinate_system': coord_system,
'creation_date': pd.Timestamp.now().isoformat(),
'processing_software': 'Geospatial AI Toolkit',
'data_access': 'Microsoft Planetary Computer via STAC'
}
)
logger.info(f"Created xarray Dataset with {len(data_arrays)} bands: {list(satellite_ds.data_vars)}")
print(satellite_ds) # Display dataset structure
else:
logger.warning("No band data available for xarray Dataset creation")2025-10-09 13:04:28,557 - INFO - Dataset: 4626×4626 pixels, 4 bands, 85,599,504 elements
2025-10-09 13:04:28,563 - INFO - Created xarray Dataset with 4 bands: ['red', 'green', 'blue', 'nir']<xarray.Dataset> Size: 171MB
Dimensions: (y: 4626, x: 4626)
Coordinates:
* y (y) float64 37kB 34.93 34.93 34.93 34.93 ... 34.5 34.5 34.5 34.5
* x (x) float64 37kB -119.9 -119.9 -119.9 ... -119.4 -119.4 -119.4
Data variables:
red (y, x) uint16 43MB 2122 2000 1958 2252 2572 ... 2214 1974 1849 1864
green (y, x) uint16 43MB 2028 1896 1860 2064 2230 ... 1828 1758 1694 1718
blue (y, x) uint16 43MB 1697 1618 1552 1698 1756 ... 1616 1530 1442 1441
nir (y, x) uint16 43MB 3966 3788 3756 3912 4260 ... 3792 3834 3966 4008
Attributes:
title: Sentinel-2 Level 2A Surface Reflectance
source: Scene: S2B_MSIL2A_20240813T183919_R070_T11SKU_20240...
acquisition_date: 2024-08-13
processing_level: L2A
crs: EPSG:32611
spatial_resolution: 10 meters
coordinate_system: geographic
creation_date: 2025-10-09T13:04:28.560520
processing_software: Geospatial AI Toolkit
data_access: Microsoft Planetary Computer via STACRasterio, Xarray, and Rioxarray
Rasterio provides lower-level, direct file access and is well-suited for basic geospatial raster operations. Xarray offers a higher-level interface, making it easier to handle metadata and perform advanced analysis. Rioxarray extends xarray by adding geospatial capabilities, effectively bridging the gap between the two approaches.
7. Scientific Visualization and Spectral Analysis
Learning Objectives
By the end of this section, you will be able to design publication-quality visualizations for satellite data analysis, understand the importance of perceptually uniform colormaps in scientific visualization, create informative multi-panel displays with appropriate context and interpretation, and calculate as well as visualize spectral indices for environmental monitoring.
7.1 Principles of Scientific Visualization for Remote Sensing
Effective satellite data visualization requires attention to perceptual accuracy, ensuring that colors accurately represent data relationships. It is important to maximize information density to provide insight with minimal cognitive load, while also preserving spatial and temporal context. Additionally, visualizations should be accessible and interpretable by a wide range of audiences.
7.2 Advanced Color Composite Creation
if band_data and all(k in band_data for k in ['B04', 'B03', 'B02']):
# Create true color RGB composite using our helper function
rgb_composite = create_rgb_composite(
red=band_data['B04'],
green=band_data['B03'],
blue=band_data['B02'],
enhance=True # Apply contrast enhancement
)
logger.info(f" RGB composite shape: {rgb_composite.shape}")
# Create false color composite if NIR band is available
false_color_composite = None
if 'B08' in band_data:
false_color_composite = create_rgb_composite(
red=band_data['B08'], # NIR in red channel
green=band_data['B04'], # Red in green channel
blue=band_data['B03'], # Green in blue channel
enhance=True
)
logger.info(f" False color composite created")
# Visualize the composites
if 'B08' in band_data:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
else:
fig, ax1 = plt.subplots(1, 1, figsize=(8, 6))
ax2 = None
# True color
ax1.imshow(rgb_composite)
ax1.set_title('True Color (RGB)', fontsize=12, fontweight='bold')
ax1.axis('off')
# Add scale bar
if 'transform' in locals() and transform:
# Calculate pixel size in meters (approximate)
pixel_size = abs(transform.a) # Assuming square pixels
scalebar_pixels = int(1000 / pixel_size) # 1km scale bar
if scalebar_pixels < rgb_composite.shape[1] / 4:
ax1.plot([10, 10 + scalebar_pixels],
[rgb_composite.shape[0] - 20, rgb_composite.shape[0] - 20],
'w-', linewidth=3)
ax1.text(10 + scalebar_pixels/2, rgb_composite.shape[0] - 30,
'1 km', color='white', ha='center', fontweight='bold')
# False color if available
if ax2 and false_color_composite is not None:
ax2.imshow(false_color_composite)
ax2.set_title('False Color (NIR-R-G)', fontsize=12, fontweight='bold')
ax2.axis('off')
ax2.text(0.02, 0.98, 'Vegetation appears red',
transform=ax2.transAxes, color='white',
fontsize=10, va='top',
bbox=dict(boxstyle='round', facecolor='black', alpha=0.5))
plt.suptitle('Sentinel-2 Composites', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
logger.info("RGB composites created successfully")
else:
logger.warning("Insufficient bands for RGB composite")2025-10-09 13:04:29,338 - INFO - RGB composite shape: (4626, 4626, 3)
2025-10-09 13:04:29,971 - INFO - False color composite created
2025-10-09 13:04:32,220 - INFO - RGB composites created successfully7.3 Calculate Vegetation Indices
if band_data and 'B08' in band_data and 'B04' in band_data:
# Calculate NDVI using our helper function
ndvi = calculate_ndvi(
nir=band_data['B08'],
red=band_data['B04']
)
# Get NDVI statistics
ndvi_stats = calculate_band_statistics(ndvi, "NDVI")
# NDVI statistics
logger.info(f"NDVI stats - Range: [{ndvi_stats['min']:.3f}, {ndvi_stats['max']:.3f}], Mean: {ndvi_stats['mean']:.3f}")
# Interpret NDVI values
vegetation_pixels = np.sum(ndvi > 0.3)
water_pixels = np.sum(ndvi < 0)
urban_pixels = np.sum((ndvi >= 0) & (ndvi <= 0.2))
total_valid = ndvi_stats['valid_pixels']
# Land cover interpretation
veg_pct = vegetation_pixels/total_valid*100
urban_pct = urban_pixels/total_valid*100
water_pct = water_pixels/total_valid*100
logger.info(f"Land cover - Vegetation: {veg_pct:.1f}%, Urban: {urban_pct:.1f}%, Water: {water_pct:.1f}%")
# Create a detailed NDVI visualization
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# NDVI map
im = ax1.imshow(ndvi, cmap='RdYlGn', vmin=-0.5, vmax=1.0)
ax1.set_title('NDVI (Normalized Difference Vegetation Index)', fontweight='bold')
ax1.axis('off')
# Add colorbar
cbar = plt.colorbar(im, ax=ax1, shrink=0.8, pad=0.02)
cbar.set_label('NDVI Value', rotation=270, labelpad=15)
# Add interpretation labels to colorbar
cbar.ax.text(1.3, 0.8, 'Dense vegetation', transform=cbar.ax.transAxes, fontsize=9)
cbar.ax.text(1.3, 0.5, 'Sparse vegetation', transform=cbar.ax.transAxes, fontsize=9)
cbar.ax.text(1.3, 0.2, 'Bare soil/Urban', transform=cbar.ax.transAxes, fontsize=9)
cbar.ax.text(1.3, 0.0, 'Water/Clouds', transform=cbar.ax.transAxes, fontsize=9)
# NDVI histogram
ax2.hist(ndvi.flatten(), bins=100, color='green', alpha=0.7, edgecolor='black')
ax2.axvline(0, color='blue', linestyle='--', alpha=0.5, label='Water threshold')
ax2.axvline(0.3, color='green', linestyle='--', alpha=0.5, label='Vegetation threshold')
ax2.set_xlabel('NDVI Value')
ax2.set_ylabel('Pixel Count')
ax2.set_title('NDVI Distribution', fontweight='bold')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
logger.info("NDVI analysis complete")
else:
logger.warning("NIR and Red bands required for NDVI calculation")2025-10-09 13:04:32,854 - INFO - NDVI stats - Range: [-1.000, 0.770], Mean: 0.277
2025-10-09 13:04:32,883 - INFO - Land cover - Vegetation: 40.8%, Urban: 29.6%, Water: 0.2%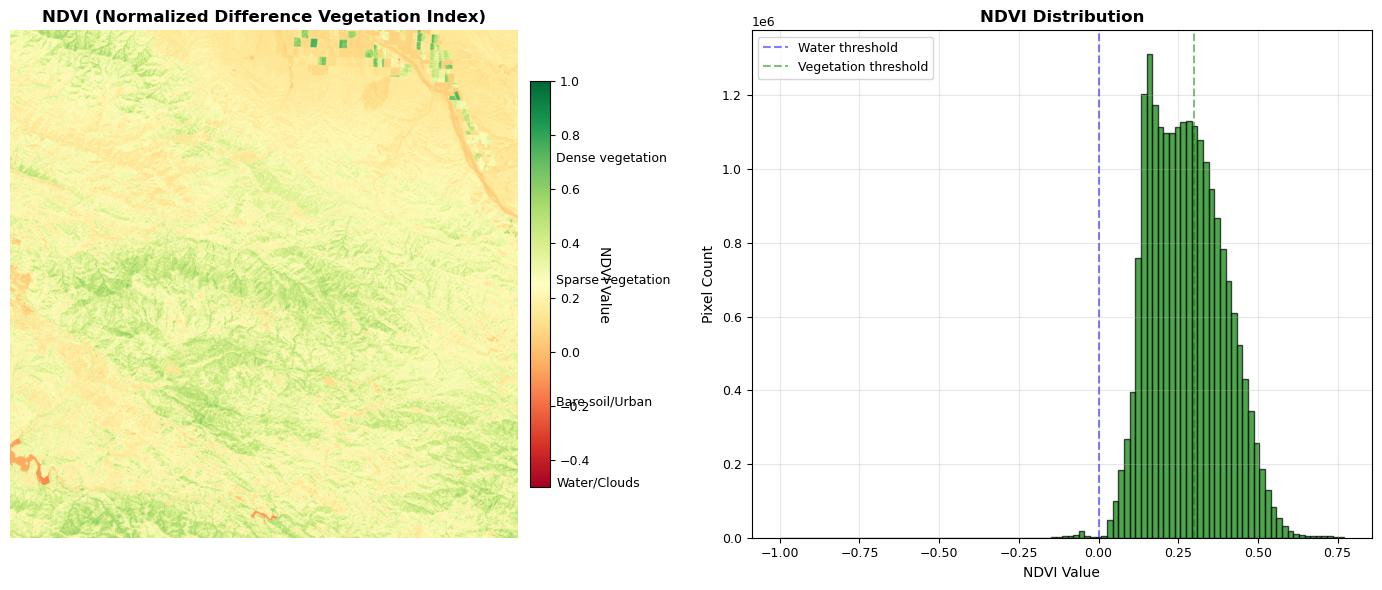
2025-10-09 13:04:34,786 - INFO - NDVI analysis completeUnderstanding NDVI Values
NDVI values range from -1 to 1, and different intervals correspond to various land cover types. Values from -1 to 0 typically indicate water bodies, clouds, snow, or shadows. Values between 0 and 0.2 are characteristic of bare soil, rock, urban areas, or beaches. NDVI values from 0.2 to 0.4 suggest sparse vegetation, such as grasslands or agricultural areas. Moderate vegetation, including shrublands and crops, is usually found in the 0.4 to 0.6 range. Dense vegetation, such as forests and healthy crops, is represented by NDVI values between 0.6 and 1.0.
A common practice in environmental studies is to use NDVI values greater than 0.3 as a mask to identify vegetated areas.
8. Band Analysis
8.2 Comprehensive Multi-band Analysis
if band_data and 'rgb_composite' in locals():
# Use our helper function for visualization
# Filter out None values from bands dictionary
valid_bands = {k: v for k, v in {'B04': band_data.get('B04'), 'B08': band_data.get('B08')}.items() if v is not None and isinstance(v, np.ndarray)}
plot_band_comparison(
bands=valid_bands,
rgb=rgb_composite if 'rgb_composite' in locals() else None,
ndvi=ndvi if 'ndvi' in locals() else None,
title="Sentinel-2 Multi-band Analysis"
)
logger.info("Multi-band comparison complete")
# Additional analysis: Band correlations
if band_data and len(band_data) > 2:
# Calculate band correlations
# Create correlation matrix
band_names = [k for k in ['B02', 'B03', 'B04', 'B08'] if k in band_data]
if len(band_names) >= 2:
# Flatten bands and create DataFrame
band_df = pd.DataFrame()
for band_name in band_names:
band_df[band_name] = band_data[band_name].flatten()
# Calculate correlations
correlations = band_df.corr()
# Plot correlation matrix
plt.figure(figsize=(8, 6))
im = plt.imshow(correlations, cmap='coolwarm', vmin=-1, vmax=1)
plt.colorbar(im, label='Correlation')
# Add labels
plt.xticks(range(len(band_names)), band_names)
plt.yticks(range(len(band_names)), band_names)
# Add correlation values
for i in range(len(band_names)):
for j in range(len(band_names)):
plt.text(j, i, f'{correlations.iloc[i, j]:.2f}',
ha='center', va='center',
color='white' if abs(correlations.iloc[i, j]) > 0.5 else 'black')
plt.title('Band Correlation Matrix', fontweight='bold')
plt.tight_layout()
plt.show()
logger.info("Band correlation analysis complete")
if 'B03' in band_names and 'B04' in band_names:
logger.info(f"Highest correlation: B03-B04 = {correlations.loc['B03', 'B04']:.3f}")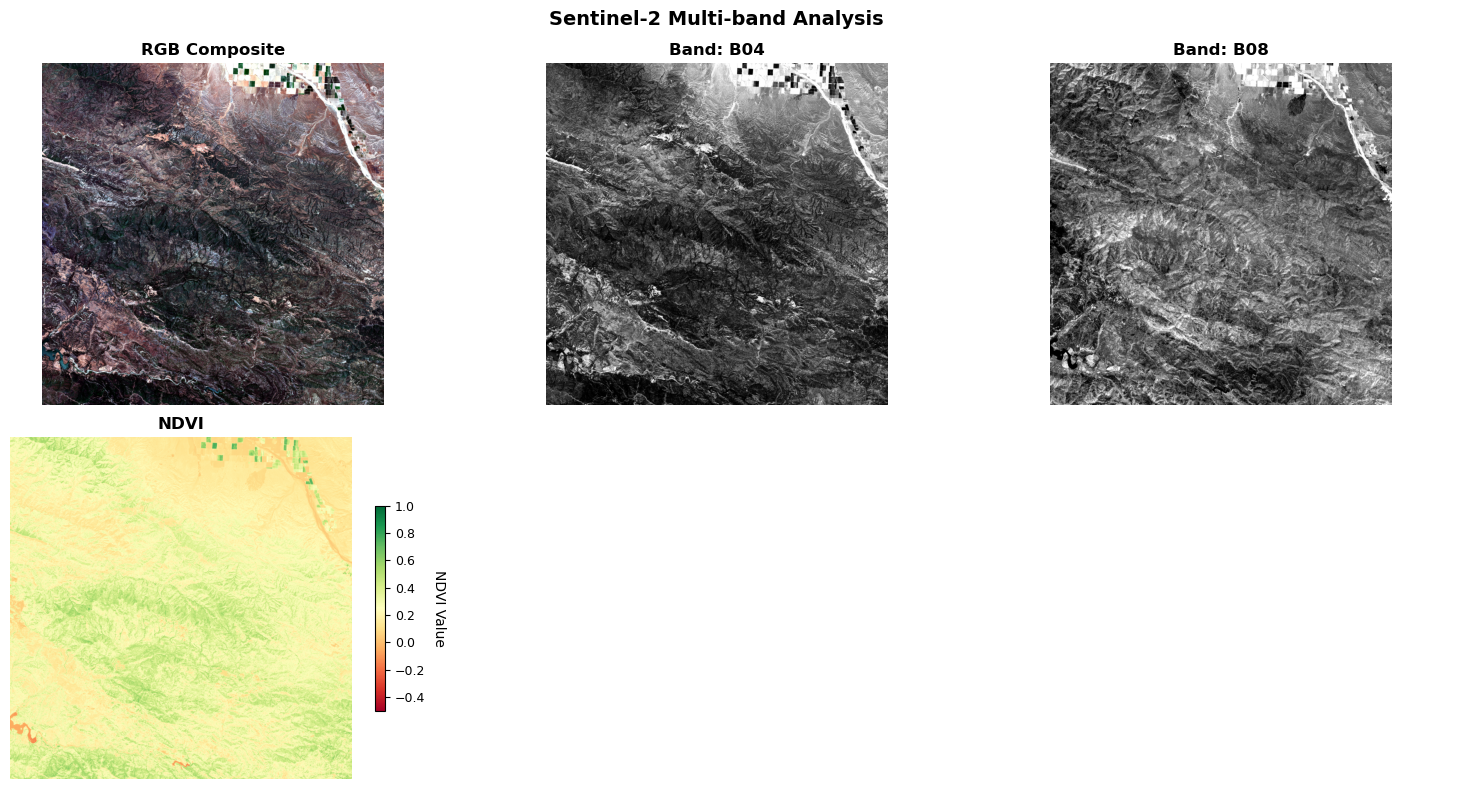
2025-10-09 13:04:41,359 - INFO - Multi-band comparison complete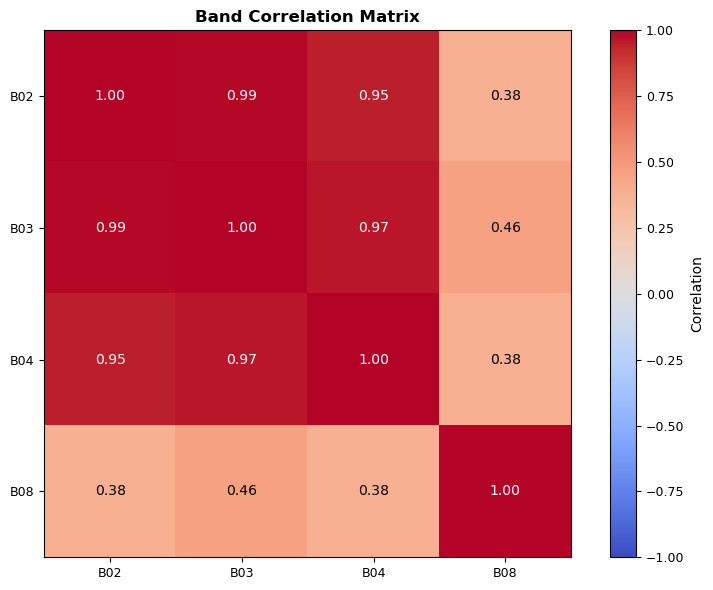
2025-10-09 13:04:42,330 - INFO - Band correlation analysis complete
2025-10-09 13:04:42,330 - INFO - Highest correlation: B03-B04 = 0.9669. Data Export and Caching
Let’s save our processed data for future use and create a reusable cache.
9.1 Export Processed Data Using Helper Functions
The next function in the code block is export_analysis_results. This function is designed to export the results of geospatial data analysis to a structured output directory. It takes several optional parameters, including arrays for NDVI and RGB composites, a dictionary of band data, geospatial transform and CRS information, scene metadata, NDVI statistics, and bounding boxes for the area of interest and any subset. The function creates the necessary output and cache directories, and then (as seen in the partial code) proceeds to export the NDVI data as a GeoTIFF file if the relevant data and metadata are provided. The function is intended to help organize and cache analysis outputs for future use or reproducibility.
from typing import Any
def export_analysis_results(
output_dir: str = "week1_output",
ndvi: Optional[np.ndarray] = None,
rgb_composite: Optional[np.ndarray] = None,
band_data: Optional[Dict[str, np.ndarray]] = None,
transform: Optional[Any] = None,
crs: Optional[Any] = None,
scene_metadata: Optional[Dict] = None,
ndvi_stats: Optional[Dict] = None,
aoi_bbox: Optional[List[float]] = None,
subset_bbox: Optional[List[float]] = None,
) -> Path:
"""Export analysis results to structured output directory.
Args:
output_dir: Output directory path
ndvi: NDVI array to export
rgb_composite: RGB composite array to export
band_data: Dictionary of band arrays to cache
transform: Geospatial transform
crs: Coordinate reference system
scene_metadata: Scene metadata dictionary
ndvi_stats: NDVI statistics dictionary
aoi_bbox: Area of interest bounding box
subset_bbox: Subset bounding box
Returns:
Path to output directory
"""
from pathlib import Path
import json
from datetime import datetime
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
cache_dir = output_path / "cache"
cache_dir.mkdir(exist_ok=True)
# Export NDVI if available
if ndvi is not None and transform is not None and crs is not None:
ndvi_path = output_path / "ndvi.tif"
save_geotiff(
data=ndvi,
output_path=ndvi_path,
transform=transform,
crs=crs,
band_names=["NDVI"],
)
logger.debug(f"Exported NDVI to {ndvi_path.name}")
# Export RGB composite if available
if rgb_composite is not None and transform is not None and crs is not None:
rgb_bands = np.transpose(rgb_composite, (2, 0, 1)) # HWC to CHW
rgb_path = output_path / "rgb_composite.tif"
save_geotiff(
data=rgb_bands,
output_path=rgb_path,
transform=transform,
crs=crs,
band_names=["Red", "Green", "Blue"],
)
logger.debug(f"Exported RGB composite to {rgb_path.name}")
# Cache individual bands
if band_data:
cached_bands = []
for band_name, band_array in band_data.items():
if band_name.startswith("B") and isinstance(band_array, np.ndarray):
band_path = cache_dir / f"{band_name}.npy"
np.save(band_path, band_array)
cached_bands.append(band_name)
logger.debug(f"Cached {len(cached_bands)} bands: {cached_bands}")
# Create metadata
metadata = {
"processing_date": datetime.now().isoformat(),
"aoi_bbox": aoi_bbox,
"subset_bbox": subset_bbox,
}
if scene_metadata:
metadata["scene"] = scene_metadata
if ndvi_stats:
metadata["ndvi_statistics"] = ndvi_stats
# Save metadata
metadata_path = output_path / "metadata.json"
with open(metadata_path, "w") as f:
json.dump(metadata, f, indent=2, default=str)
logger.info(f"Analysis results exported to: {output_path.absolute()}")
return output_path9.2 Reloading Data
To reload your processed data, you can use the load_week1_data function provided below. This function reads the exported metadata, NDVI raster, and any cached bands from the specified output directory. Here’s how you can use it:
def load_week1_data(output_dir: str = "week1_output") -> Dict[str, Any]:
"""Load processed data from Week 1."""
from pathlib import Path
import json
import numpy as np
import rasterio
output_path = Path(output_dir)
if not output_path.exists():
raise FileNotFoundError(f"Directory not found: {output_path}")
data = {}
# Load metadata
metadata_path = output_path / "metadata.json"
if metadata_path.exists():
with open(metadata_path) as f:
data["metadata"] = json.load(f)
# Load NDVI
ndvi_path = output_path / "ndvi.tif"
if ndvi_path.exists():
with rasterio.open(ndvi_path) as src:
data["ndvi"] = src.read(1)
data["transform"] = src.transform
data["crs"] = src.crs
# Load cached bands
cache_dir = output_path / "cache"
if cache_dir.exists():
data["bands"] = {}
for band_file in cache_dir.glob("*.npy"):
band_name = band_file.stem
data["bands"][band_name] = np.load(band_file)
return data
# Export the analysis results
scene_meta = None
if "best_scene" in locals():
scene_meta = {
"id": best_scene.id,
"date": best_scene.properties["datetime"],
"cloud_cover": best_scene.properties["eo:cloud_cover"],
"platform": best_scene.properties.get("platform", "Unknown"),
}
output_dir = export_analysis_results(
ndvi=ndvi if "ndvi" in locals() else None,
rgb_composite=rgb_composite if "rgb_composite" in locals() else None,
band_data=band_data if "band_data" in locals() else None,
transform=transform if "transform" in locals() else None,
crs=crs if "crs" in locals() else None,
scene_metadata=scene_meta,
ndvi_stats=ndvi_stats if "ndvi_stats" in locals() else None,
aoi_bbox=santa_barbara_bbox if "santa_barbara_bbox" in locals() else None,
subset_bbox=subset_bbox if "subset_bbox" in locals() else None,
)
logger.info("Data exported - use load_week1_data() to reload")2025-10-09 13:04:43,356 - INFO - Saved GeoTIFF: week1_output/ndvi.tif
2025-10-09 13:04:52,066 - INFO - Saved GeoTIFF: week1_output/rgb_composite.tif
2025-10-09 13:04:52,362 - INFO - Analysis results exported to: /Users/kellycaylor/dev/geoAI/book/chapters/week1_output
2025-10-09 13:04:52,362 - INFO - Data exported - use load_week1_data() to reload10. Conclusion: From Foundations to Frontiers
What You’ve Accomplished
You’ve successfully built a production-ready geospatial AI toolkit that demonstrates both technical excellence and software engineering best practices. This foundation will serve you throughout your career in geospatial AI.
🎉 Outstanding Achievement! You’ve progressed from basic satellite data access to building a sophisticated, enterprise-grade geospatial analysis system.
10.1 Core Competencies Developed
Technical Mastery:
- 🛠️ Enterprise-Grade Toolkit: Built 13+ production-ready functions for geospatial AI workflows
- 🔐 Security-First Architecture: Implemented robust authentication and error handling patterns
- 🌍 Mastered STAC APIs: Connected to planetary-scale satellite data with proper authentication
- 📡 Loaded Real Satellite Data: Worked with actual Sentinel-2 imagery, not just sample data
- 🎨 Created Publication-Quality Visuals: RGB composites, NDVI maps, and interactive visualizations
- 📊 Performed Multi-band Analysis: Calculated vegetation indices and band correlations
- 🗺️ Built Interactive Maps: Folium maps with measurement tools and multiple basemaps
- 💾 Established Data Workflows: Export functions and caching for reproducible analysis
Key Technical Skills Gained:
- Authentication: Planetary Computer API tokens for enterprise-level data access
- Error Handling: Robust functions with retry logic and fallback options
- Memory Management: Subsetting and efficient loading of large raster datasets
- Geospatial Standards: Working with CRS transformations and GeoTIFF exports
- Code Documentation: Well-documented functions with examples and type hints
10.2 Real-World Applications
Your helper functions are now ready for:
- 🌱 Environmental Monitoring: Track deforestation, urban growth, crop health
- 🌊 Disaster Response: Flood mapping, wildfire damage assessment
- 📊 Research Projects: Time series analysis, change detection studies
- 🏢 Commercial Applications: Agricultural monitoring, real estate analysis
10.3 Week 2 Preview: Rapid Preprocessing Pipelines
Next week, we’ll scale up using your new toolkit:
- Batch Processing: Handle multiple scenes and time series
- Cloud Masking: Automatically filter cloudy pixels
- Mosaicking: Combine scenes into seamless regional datasets
- Analysis-Ready Data: Create standardized data cubes for ML
- Performance Optimization: Parallel processing and dask integration
Steps to try:
- Modify the
santa_barbara_bboxto your area of interest - Use
search_sentinel2_scenes()to find recent imagery - Run the complete analysis pipeline
- Export your results and compare seasonal changes
10.4 Essential Resources
Data Sources:
- Microsoft Planetary Computer Catalog - Free satellite data
- STAC Browser - Explore STAC catalogs
- Earth Engine Data Catalog - Alternative data source
Technical Documentation:
- Rasterio Documentation - Geospatial I/O
- Xarray Tutorial - Multi-dimensional arrays
- STAC Specification - Metadata standards
- Folium Examples - Interactive mapping
Community:
- Pangeo Community - Open source geoscience
- STAC Discord - STAC community support
- PyData Geospatial - Python geospatial ecosystem
Remember: Your helper functions are now your superpower! 🦸 Use them to explore any area on Earth with just a few lines of code.